●corrplot
関数 corrplot() は、入力変数間の相関関係を可視化する散布図行列 (Correlogram) を自動生成します。対角線上に各変数の「ヒストグラム」、下三角行列に「散布図」と「回帰直線」を、上三角行列に「2 次元ヒストグラム」を配置したグラフを 1 つのコマンドで描画できます。
corrplot(data, ...)
一番簡単な方法は引数 data に行列を渡すことです。各変数が列に対応します。簡単な例を示しましょう。
julia> using StatsPlots
julia> data = randn(100, 4)
100×4 Matrix{Float64}:
... 省略 ...
julia> corrplot(data)
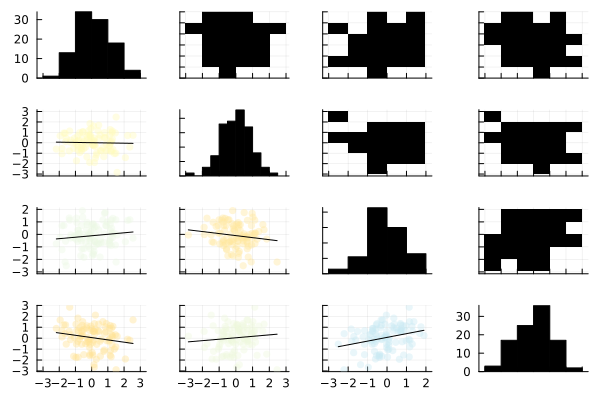 corrplot()
corrplot()
オプション markercolor にカラーグラデーションを渡すことで、散布図の点の相関度合いに応じた色付けを変更できます。デフォルトでは、正の相関が青、負の相関が赤、無相関が黄にマッピングされます。
なお、M.Hiroi の環境 (Julia ver 1.12.6, StatsPlots v0.15.8) では、 StatsPlots.jl の マニュアル のように、2 次元ヒストグラムに色が付きません。他の環境では正常に動作するかもしれません。ご自身の環境でご確認くださいませ。
StatsPlots.jl には、同様の相関可視化関数として cornerplot() も用意されています。
cornerplot(data, ...)
julia >cornerplot(data)
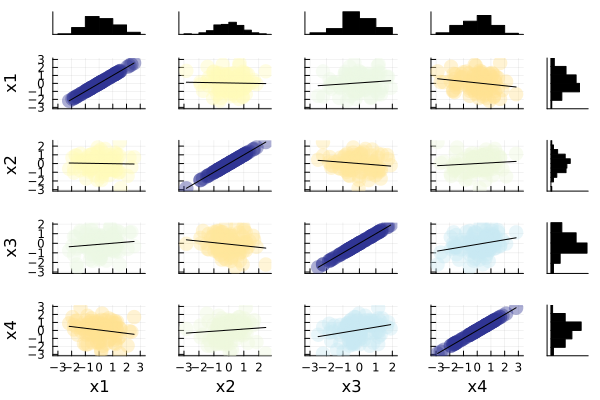 cornerplot()
cornerplot()
オプション compact=true を設定すると、自分自身の相関図と上三角部分を非表示にすることができます。
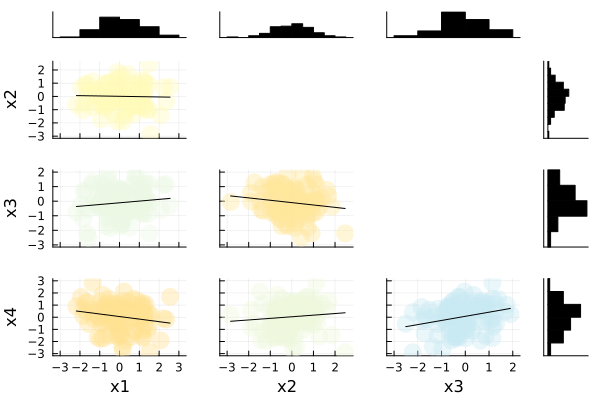 cornerplot(data, compact=true)
cornerplot(data, compact=true)
DataFrams.jl を使う場合はマクロ @df を使うと簡単です。
リスト : 正の相関と負の相関
# 強い正の相関
data1 = [
[4.6, 5.5], [0.0, 1.7], [6.4, 7.2], [6.5, 8.3],
[4.4, 5.7], [1.1, 1.1], [2.8, 4.1], [5.1, 6.7],
[3.4, 5.0], [5.8, 6.6], [5.7, 6.3], [5.5, 5.6],
[7.9, 8.7], [3.0, 3.6], [6.8, 8.2], [6.2, 6.2],
[4.0, 5.0], [8.6, 9.5], [7.5, 8.9], [1.3, 2.6],
[6.3, 7.4], [3.1, 5.0], [6.1, 8.2], [5.3, 6.6],
[3.9, 5.1], [5.8, 7.0], [2.6, 3.5], [4.8, 6.3],
[2.2, 2.9], [5.3, 6.9]
]
# 強い負の相関
data2 = [
[6.1, 3.7], [3.9, 7.5], [8.6, 1.7], [5.9, 3.9],
[3.5, 5.5], [7.0, 2.4], [0.9, 9.8], [0.0, 10.2],
[5.2, 4.2], [3.5, 6.5], [6.9, 3.2], [4.3, 5.9],
[5.0, 5.9], [7.4, 3.3], [3.1, 6.6], [4.0, 6.2],
[6.9, 2.9], [4.8, 5.0], [10.6, 0.0], [4.7, 4.3],
[2.9, 7.6], [7.2, 2.2], [3.6, 6.0], [5.5, 4.3],
[5.5, 4.5], [6.9, 3.2], [5.8, 3.6], [4.8, 4.6],
[7.3, 2.5], [4.7, 5.4]
]
julia> using DataFrames
julia> df = DataFrame(
x1 = [x[1] for x = data1],
y1 = [x[2] for x = data1],
x2 = [x[1] for x = data2],
y2 = [x[2] for x = data2])
30×4 DataFrame
... 省略 ...
julia> @df df corrplot([:x1 :y1 :x2 :y2])
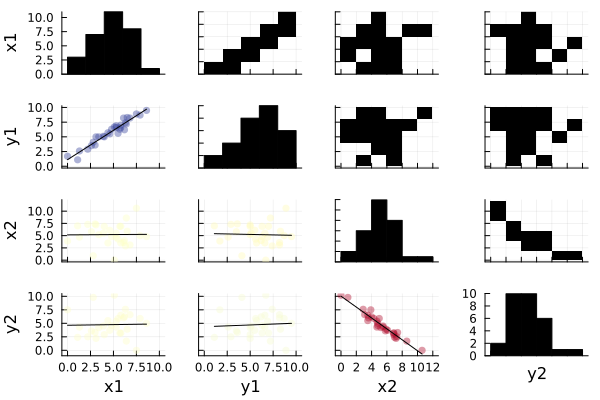 正の相関と負の相関
正の相関と負の相関
●ボックスプロット
ボックスプロット (box plot, 箱ひげ図) は、データのばらつきや分布の偏りを「箱」と「ひげ」で視覚的に表現する統計グラフです。データを小さい順に並べて 4 等分した「四分位数」をベースに、主に 5 つの統計量を示しています。
- 最小値 : ひげの左端 (または下端) の線
- 第 1 四分位数 Q1 : 箱の左端 (または下端) の線
データを小さい順に並べたとき、下から 1 / 4 番目にあたる値 - 中央値 (メディアン) Q2 : 箱の中にある、最も太い縦線 (または横線)
データを半分に分ける 1 / 2 番目にあたる値 - 第 3 四分位数 Q3 : 箱の右端 (または上端) の線
データを小さい順に並べたとき、下から 3 / 4 番目にあたる値 - 最大値:ひげの右端 (または上端) の線
- 外れ値:ひげの範囲から大きく外れた、ポツンと離れてプロットされる点のこと
ボックスプロットは StatsPlots.jl の関数 boxplot() を使うと簡単に描画することができます。配列だけではなく、行列やデータフレーム (DataFrame) を扱うことができます。
boxplot(x, data, ...) boxplot(data, ...)
主なオプションを以下にに示します。
- fillcolor: 箱の色 (:blue など)
- fillalpha: 箱の透明度 (0.0 〜 1.0)
- orientation: :horizontal に指定すると横向きの箱ひげ図になる
- outliers: 外れ値の表示 / 非表示の切り替え
data が行列の場合、各列が 1 つのグループとして扱われます。x は x 軸の目盛り (ラベル) を指定します。簡単な例を示しましょう。
julia> df = DataFrame(A = randn(20), B = randn(20), C = randn(20), D = randn(20)) 20×4 DataFrame julia> @df df boxplot(["A"], :A)
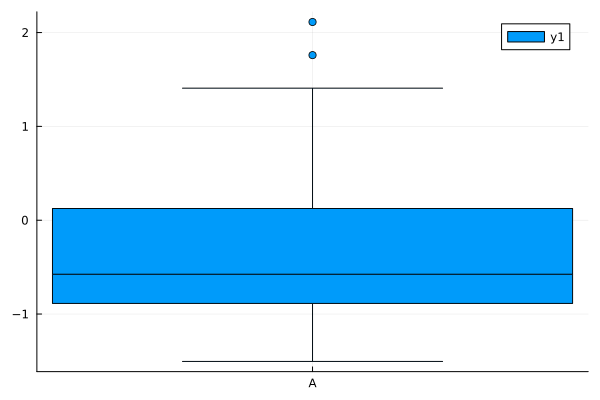 ボックスプロット (1)
ボックスプロット (1)
julia> @df df boxplot!(["B"], :B) julia> @df df boxplot!(["C"], :C) julia> @df df boxplot!(["D"], :D)
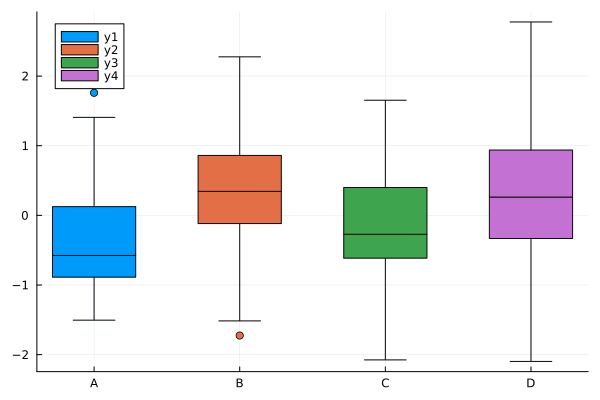 ボックスプロット (2)
ボックスプロット (2)
なお、次のようにデータフレームを行列に変換して、複数のデータを同時に描画することもできます。
julia> boxplot(Array(df), xticks=(1:4, ["A", "B", "C", "D"])
結果は同じなので省略します。
行列 data を平坦化する場合、各要素に対応する x 軸のラベルを格納した配列を、引数 x に渡してください。
julia> @df df boxplot(repeat(["A", "B", "C", "D"], inner=20), [:A; :B; :C; :D])
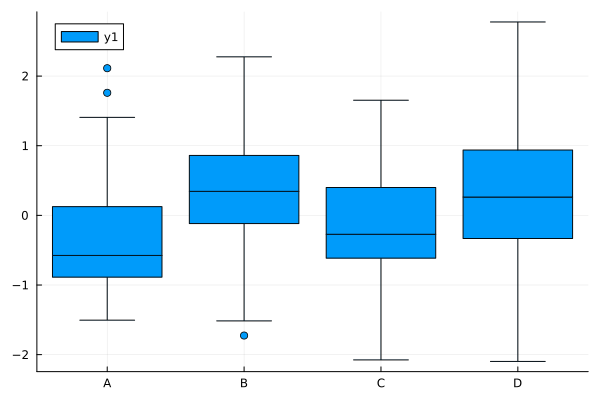 ボックスプロット (3)
ボックスプロット (3)
●ドットプロット
ドットプロット (dotplot) は、カテゴリごとのデータの分布を個々の「点 (ドット)」の集まりとして可視化するグラフです。バイオリン図や箱ひげ図の上に重ねて、実際のデータやその偏りなどを同時に見せたいときによく使われます。ドットプロットは StatsPlots.jl の関数 dotplot() で描画することができます。配列だけではなく、行列やデータフレーム (DataFrame) を扱うことができます。
boxplot(x, data, ...) boxplot(data, ...)
引数 x, data は boxplot() と同じです。主なオプションを以下にに示します。
- markercolor (mc): ドットの色
- markersize (ms): ドットの大きさ (数値)
- markeralpha (ma): 透過度 (0.0 〜 1.0)
- markerstrokewidth (msw): 枠線の太さ (0 にすると枠線なし)
- marker=(サイズ, 透過度, 色) などでも調整可能
dotplot はドットが重ならないように横方向に適当にばらまいて描画されます。これをジッター (jitter) といい、オプション mode で動作を変更することができます。
- :density (デフォルト)
バイオリン図の形状 (カーネル密度) に合わせて、データが多い場所ほど横に広がるようにプロットする - :uniform
カテゴリの列幅いっぱいに一様にランダム分散させる - :none
一切散らばらせず、中央の一本の直線上にドットを並べる
この他に以下のオプションがあります。
- markers_per_bin: 1 行に並べるドットの最大数
- binwidth: ドットを配置する横幅の広がり
- orientation: :horizontal に指定すると横向きのプロットになる
簡単な実行例を示します。
julia> using DataFrames, StatsPlots julia> df = DataFrame(randn(20, 4), ["A", "B", "C", "D"]) 20×4 DataFrame ... 略 ... julia> @df df dotplot(["A"], :A)
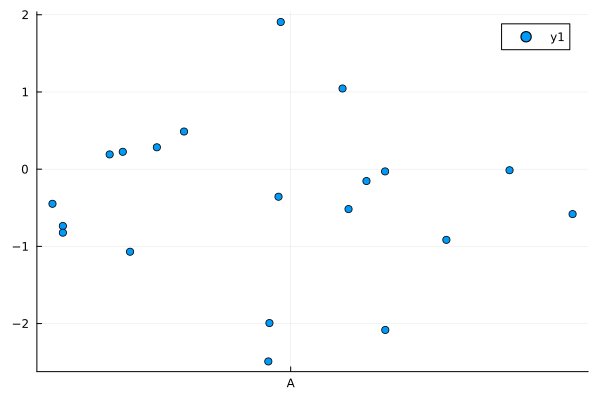 ドットプロット (1)
ドットプロット (1)
julia> @df df dotplot!(["B"], :B) julia> @df df dotplot!(["C"], :C) julia> @df df dotplot!(["D"], :D)
 ドットプロット (2)
ドットプロット (2)
julia> dotplot(Array(df), mode=:none, xticks=(1:4, ["A", "B", "C", "D"]))
 ドットプロット (3)
ドットプロット (3)
julia> @df df boxplot(repeat(["A", "B", "C", "D"], inner=20), [:A; :B; :C; :D], fillalpha=0.4) julia> @df df dotplot!(repeat(["A", "B", "C", "D"], inner=20), [:A; :B; :C; :D], fillalpha=0.4)
 ドットプロットとボックスプロットの重ね合わせ
ドットプロットとボックスプロットの重ね合わせ
●バイオリン図
バイオリン図 (violin plot) は、データの分布とその統計的な要約を同時に表現できるグラフです。一般的には、箱ひげ図にカーネル密度プロット (ヒストグラムを滑らかにしたもの) を融合させた構造をしており、データの「偏り」や「山 (モード) の数」を直感的に把握できます。左右対称の形状が弦楽器のバイオリンに似ていることからこの名が付けられました。
バイオリン図はデータの分布密度を外側の膨らみ (バイオリン部分) で表します。横幅が広い部分はデータが集中している (頻度が高い) ことを表し、狭い部分はデータが少ないことを表します。
Julia の場合、StatsPlots.jl の関数 violin() を使うと簡単にバイオリン図を描画することができます。
boxplot(x, data, ...) boxplot(data, ...)
引数 x, data は boxplot() と同じです。なお、violin() が描画するのはデータの分布密度だけです。箱ひげ図もいっしょに描画したい場合は boxplot!() を呼び出す必要があります。
主なオプションを以下に示します。
- side = :both (デフォルト)
バイオリンの形状を左右どちらに描くか指定します。
:both (デフォルト) 両側, :left 左側だけ, :right 右側だけ - trim = true
データの最小値・最大値の外側まで密度曲線を「裾野」のように伸ばすかどうか
true でデータの存在する範囲でプロットをスパッと切り落とします。
false にすると端が滑らかに消えていく形状になります。 - bandwidth = ...
曲線の滑らかさを決めるカーネル密度のバンド幅 (窓幅) を数値で指定します。
値を小さくするとギザギザになり、大きくすると滑らかになります。 - color(または fillcolor): 塗りつぶしの色を指定 (:blue, :lightblue, "#FF5733" など)
- alpha(または fillalpha): 塗りつぶしの透明度 (0.0 ~ 1.0)
- linecolor: 外枠の線の色
- linewidth: 外枠の線の太さ
- orientation = :vertical (デフォルト)
グラフの向き。:vertical (縦向き), :horizontal に変えると、横向きのバイオリン図になる
簡単な実行例を示します。
julia> using DataFrames, StatsPlots julia> df = DataFrame(randn(30, 4), ["A", "B", "C", "D"]) 30×4 DataFrame ... 省略 ... julia> @df df violin(["A"], :A)
 バイオリン図 (1)
バイオリン図 (1)
julia> @df df violin!(["B"], :B) julia> @df df violin!(["C"], :C) julia> @df df violin!(["D"], :D)
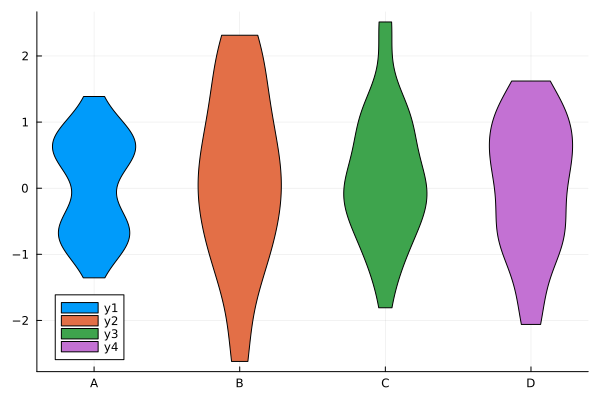 バイオリン図 (2)
バイオリン図 (2)
julia> violin(Array(df), trim=false, xticks=(1:4, ["A", "B", "C", "D"]))
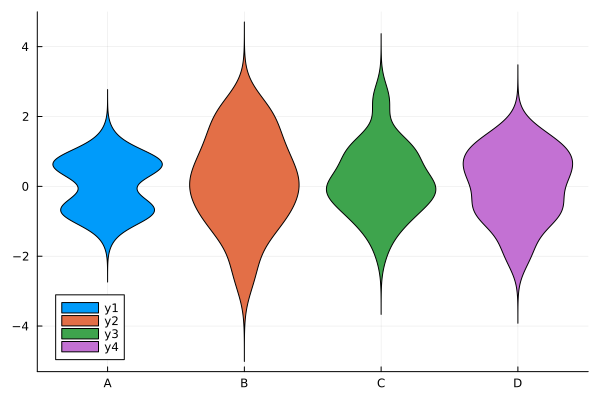 バイオリン図 (3)
バイオリン図 (3)
julia> @df df violin(repeat(["A", "B", "C", "D"], inner=30), [:A; :B; :C; :D], fillalpha=0.4) julia> @df df boxplot!(repeat(["A", "B", "C", "D"], inner=30), [:A; :B; :C; :D], fillalpha=0.4)
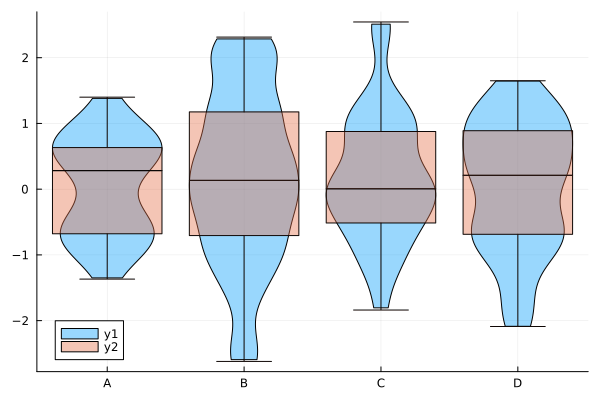 バイオリン図との重ね合わせ (1)
バイオリン図との重ね合わせ (1)
julia> @df df dotplot!(repeat(["A", "B", "C", "D"], inner=30), [:A; :B; :C; :D], fillalpha=0.4)
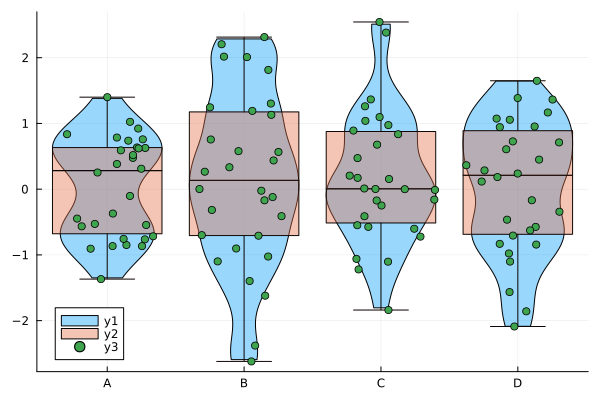 バイオリン図との重ね合わせ (2)
バイオリン図との重ね合わせ (2)
●density
関数 density (density!) は、データの確率密度関数を推定 (カーネル密度推定) し、滑らかな曲線で描画します。簡単に言うと、ヒストグラムを滑らかにした曲線になります。
density(data, ...)
確率密度関数なので、曲線と x 軸の間の面積が確率を表します (合計 1.0)。確率密度については拙作のページ Algorithms with Python: 統計学の基礎知識 [1] 「連続型の確率分布」をお読みください。
簡単な例を示しましょう。
julia> using StatsPlots
julia> a = randn(100)
100-element Vector{Float64}:
... 略 ...
julia> density(a)
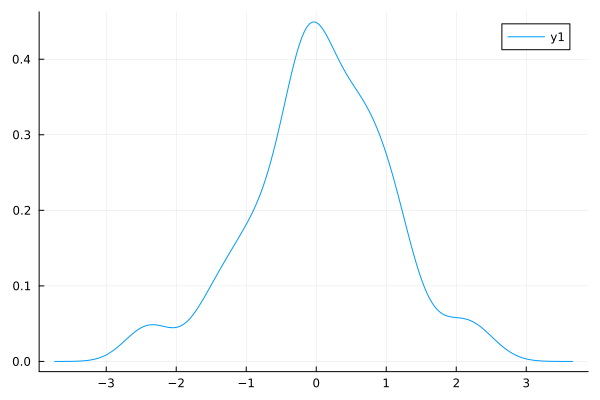 確率密度関数 (1)
確率密度関数 (1)
julia> histogram(a)
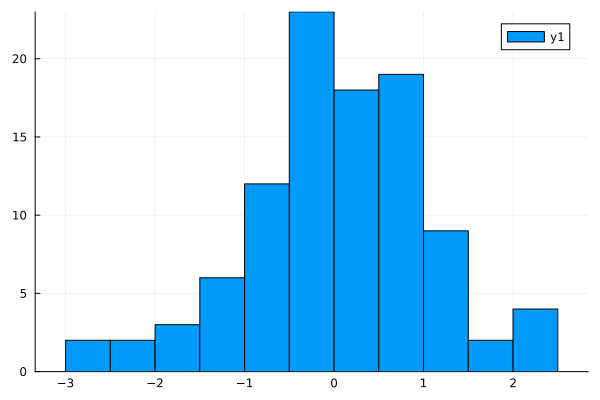 ヒストグラム
ヒストグラム
ヒストグラムと重ねる場合、histogram() のオプション normed に true を指定して、面積の合計を 1 にするのがポイントです。
julia> histogram(a, normed=true, alpha=0.5, label="Histogram") julia> density!(a, linewidth=2, label="Density Line")
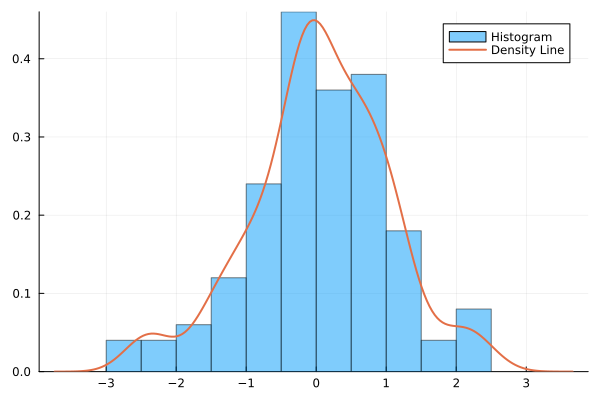 重ね合わせ
重ね合わせ
julia> b = randn(100) .+ 2
100-element Vector{Float64}:
... 略 ...
julia> c = randn(100) .+ 4
100-element Vector{Float64}:
... 略 ...
julia> density(a)
julia> density!(b)
julia> density!(c)
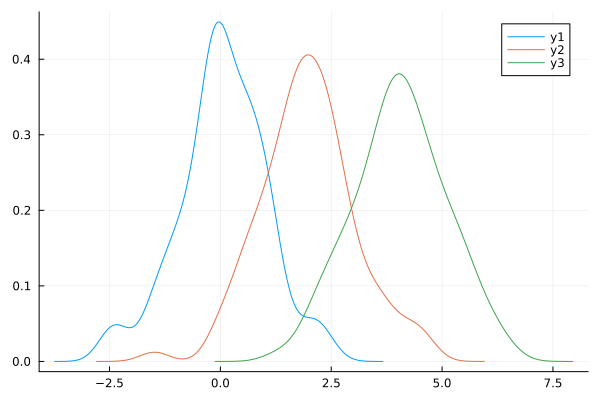 確率密度関数 (2)
確率密度関数 (2)
●正規分布
次の式で表される確率分布を「正規分布」といいます。
これを平均 \(\mu\)、分散 \(\sigma^2\) の正規分布といい、\(N(\mu, \sigma^2)\) と略記します。特に、\(N(0, 1)\) を「標準正規分布」といいます。この式を Julia でプログラムすると、次のようになります。
リスト : 正規分布 (norm.jl) function make_norm(m, s2) x -> 1 / sqrt(2 * pi * s2) * exp(- ((x - m) ^ 2) / (2 * s2)) end
関数 make_norm() の引数 m が平均 \(\mu\)、s2 が分散 \(\sigma^2\) を表します。分散のかわりに \(\sigma\) を渡す場合もあります。返り値が \(N(\mu, \sigma^2)\) を表す関数になります。正規分布は次の図に示すような釣鐘状の曲線 (ベル・カープ) になります。
julia> using StatsPlots
julia> include("norm.jl")
make_norm (generic function with 1 method)
julia> plot(make_norm(0, 1), lw = 2.0)
julia> plot!(make_norm(1, 2), lw = 2.0)
julia> plot!(make_norm(-2, 0.5), lw = 2.0)
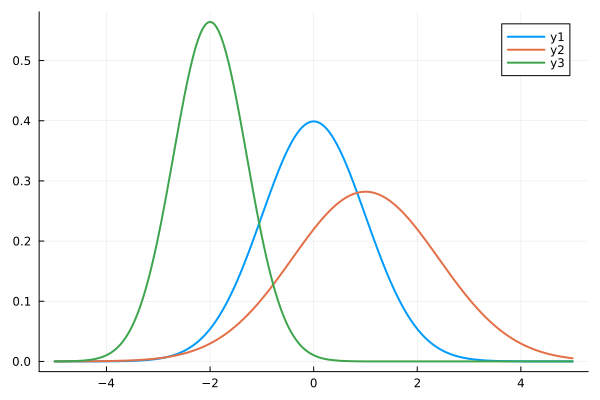 正規分布 (1)
正規分布 (1)
青線が N(0, 1)、赤線が N(1, 2)、緑線が N(-2. 0.5) です。正規分布は、平均値のデータが一番多く、分散の値が小さいほど平均値にデータが集まるので、ベル・カーブの頂点が高くなります。分散の値が大きくなると、ベル・カーブの頂点は低くなり裾野が広がります。ようするに、分散の値だけで正規分布の形が決まるわけです。
正規分布の場合、\(-\sigma \lt x \lt \sigma\) の確率が 68.26 % で、\(-2\sigma \lt x \lt 2\sigma\) の確率が 95.44 % になります。したがって、下図のように標準正規分布では \(-1 \lt x \lt 1\) の確率が 68.26 % で、\(-2 \lt x \lt 2\) の確率が 95.44 % になります。
julia> plot(make_norm(0, 1), lw = 2.0) julia> plot!(make_norm(0, 1), -1, 1, fillrange = 0, fillalpha = 0.5)
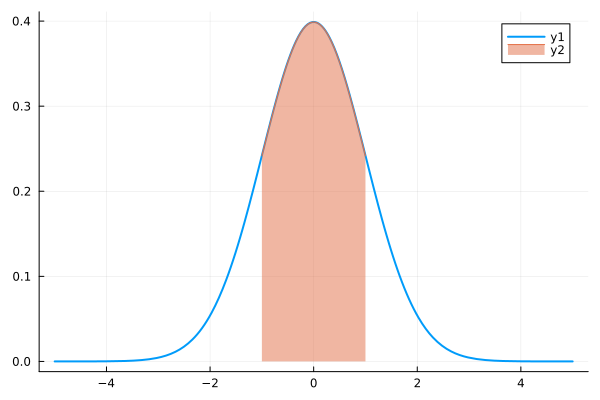 正規分布 (2)
正規分布 (2)
julia> plot(make_norm(0, 1), lw = 2.0) julia> plot!(make_norm(0, 1), -2, 2, fillrange = 0, fillalpha = 0.5)
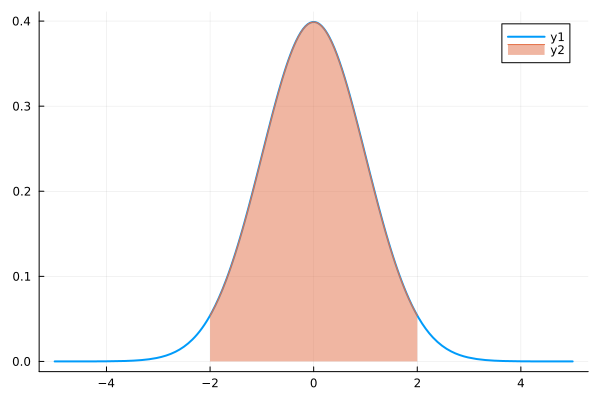 正規分布 (3)
正規分布 (3)
ところで、今回は正規分布を生成する関数 make_norm() を作りましたが、Julia のパッケージ Distributions.jl をインストールすると、正規分布だけではなく、いろいろな確率分布を簡単に扱うことができます。
(@v1.12) pkg> add Distributions
(@v1.12) pkg> st Status `~/.julia/environments/v1.12/Project.toml` [336ed68f] CSV v0.10.16 [a93c6f00] DataFrames v1.8.2 [31c24e10] Distributions v0.25.125 [91a5bcdd] Plots v1.41.6 [f3b207a7] StatsPlots v0.15.8 [bd369af6] Tables v1.12.1
M.Hiroi の環境では Distributions v0.25.125 がインストールされました。もしも、インストールでエラーが発生する場合は、ライブラリをアップデートするとうまくいく場合があります。
(@v1.12) pkg> update
正規分布はコンストラクタ Normal(\(\mu, \sigma\)) で生成します。第 2 引数は分散ではないことに注意してください。これで正規分布 \(N(\mu, \sigma)\) を表すオブジェクトが生成されます。StatsPlots.jl の描画関数は、これをそのまま引数に受け取ることができます。また、Normal() とすると、N(0, 1) の正規分布が生成されます。
簡単な例を示しましょう。
julia> using StatsPlots, Distributions julia> plot(Normal(), fillrange = 0, fillalpha = 0.5) julia> plot!(Normal(1, sqrt(2)), fillrange = 0, fillalpha = 0.5) julia> plot!(Normal(-2, sqrt(0.5)), fillrange = 0, fillalpha = 0.5)
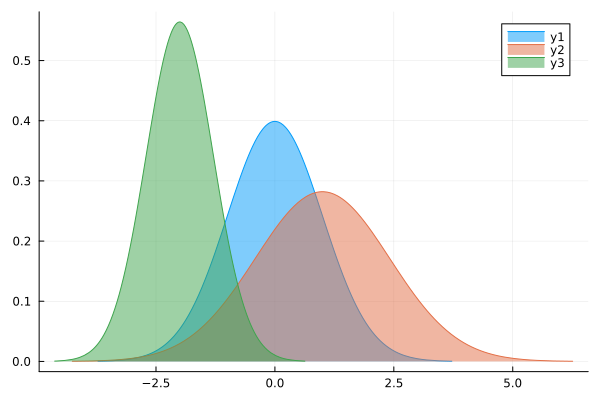 正規分布 (4)
正規分布 (4)
定義した確率分布から値を抽出するには関数 rand() を使います。
rand(dist) => データ rand(dist, N) => 大きさ N のベクタ
簡単な例を示しましょう。
julia> d = Normal(2, sqrt(0.5))
Normal{Float64}(μ=2.0, σ=0.7071067811865476)
julia> x = rand(d, 200)
200-element Vector{Float64}:
... 略 ...
julia> histogram(x, normed=true, alpha=0.5, label="Histogram")
julia> density!(x, linewidth=2, label="Density Line")
 正規分布 (5)
正規分布 (5)
この他にも Distributions.jl には便利な機能が多数用意されています。興味のある方は Distributions Package をお読みくださいませ。