関数の使い方
今回は関数の基本的な使い方について説明します。関数を使いこなすことができるようになると、ちょっと複雑なプログラムでも簡単に作ることができます。
●関数定義
関数を定義するときは function 文を使います。簡単な例として、数を 2 乗する関数を作ってみましょう。リスト 1 を見てください。
リスト 1 : 数を 2 乗する関数 function square(x) return x * x end
function 文の構文を図 1 に示します。function 文は図 2 のように数式と比較するとわかりやすいでしょう。
function 名前(仮引数名, ...) 処理A 処理B ... end 図 1 : 関数定義

それでは実際に実行してみます。
> function square(x) return x * x end > square(10) 100
関数を定義するには名前が必要です。function 文の次に関数の名前を記述します。Lua の場合、function 文で定義された処理内容は、名前で指定した変数に格納されます。変数 square の値は、たとえば次のように表示されます。
> square function: 0x7fffda8d3ca0
関数名の次にカッコで引数名を指定します。引数を取らない関数は () と記述します。Lua の場合、カッコを省略することはできません。それから、関数定義で使用する引数のことを「仮引数」、実際に与えられる引数を「実引数」といいます。 seuare の定義で使用した x が仮引数で、square(10) の 10 が実引数となります。
そして、カッコの後ろのブロックの中で処理内容を記述します。square の処理は return x * x の一つだけですが、ブロックの中では複数の処理を記述することができます。Lua の場合、関数の返り値は return 文を使って返します。これはC言語と同じです。Perl のように、ブロックの最後で実行された処理結果が返り値とはなりません。return のない関数、または return に引数がない場合は何も返しません。
●複数の値を返す (多値)
また、Lua の関数は複数の値を返すことができます。Common Lisp / Scheme では、この機能を「多値 (Multiple Values)」といいます。Lua の場合、次に示すように return に複数の値を指定するだけです。
> function foo() return 1, 2, 3 end > a, b, c = foo() > a 1 > b 2 > c 3
関数の返り値が左辺の変数よりも多い場合、余分な返り値は捨てられます。また、左辺の変数が多い場合、余った変数には nil がセットされます。
> d = foo() > d 1 > e, f, g, h = foo() > e 1 > f 2 > g 3 > h nil
これらの動作は Common Lisp の多値とほぼ同じです。Common Lisp で多値を受け取る場合、multiple-value-bind といった専用の関数が必要になります。Lua は多重代入を使って多値を簡単に受け取ることができるので、Common Lisp よりも気軽に使えると思います。
●ローカル変数とグローバル変数
それでは、ここで変数 x に値が代入されている場合を考えてみましょう。次の例を見てください。
> x = 5 > x 5 > square(10) ?
結果はどうなると思いますか。x には 5 がセットされているので 5 の 2 乗の 25 になるのでしょうか。これは 10 の 2 乗が計算されて、結果は 100 になります。そして、square を実行したあとでも変数 x の値は変わりません。
> square(10) 100 > x 5
square の仮引数 x は、その関数が実行されている間だけ有効です。このような変数を「ローカル変数 (local variable)」もしくは「局所変数」といいます。これに対し、最初に変数 x に値を代入した場合、その値は一時的なものではなく、その値は Lua を実行している間ずっと存在しています。このような変数を「グローバル変数 (golbal variable)」もしくは「大域変数」といいます。
Lua は変数の値を求めるとき、それがローカル変数であればその値を使います。ローカル変数でなければ、グローバル変数の値を使います。次の例を見てください。
> x 10 > y 20 > function foo(x) print(x); print(y) end > foo(100) 100 20
最初にグローバル変数として x と y に値を代入します。関数 foo は仮引数として x を使います。foo を実行すると、x はローカル変数なので値は実引数の 100 になります。y はローカル変数ではないのでグローバル変数の値 20 になります。図 3 を見てください。
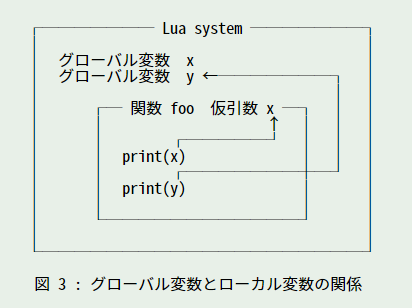
このように、関数内ではローカル変数の値を優先します。プログラムを作る場合、関数を部品のように使います。ある関数を呼び出す場合、いままで使っていた変数の値が勝手に書き換えられると、呼び出す方が困ってしまいます。部品であるならば、ほかの処理に影響を及ぼさないように、自分自身の中で処理を完結させることが望ましいのです。これを実現するための必須機能がローカル変数なのです。
●ローカル変数の定義と有効範囲
Lua の場合、関数の引数はローカル変数になりますが、local 文で宣言した変数もローカル変数になります。
local 変数1, ..., 変数N local 変数1, ..., 変数N = 値1, ..., 値N
簡単な例を示しましょう。
リスト 2 : 要素の合計値を求める
function sum(ary)
local total = 0
for i = 1, #ary do
total = total + ary[i]
end
return total
end
関数 sum の引数 ary には要素が数値の配列を渡します。変数 total は local で宣言されているのでローカル変数になります。なお、for 文で使う変数 i もローカル変数になります。sum の処理内容は簡単です。最初に、変数 total を 0 に初期化します。次に、for 文で配列の要素を順番に取り出して total に加算していきます。最後に return で total の値を返します。実際に実行すると次のようになります。
> sum({1,2,3,4,5})
15
ローカル変数が値を保持する期間のことを、変数の「有効範囲 (scope : スコープ)」といいます。Lua の場合、ローカル変数はブロックの中であればどこででも宣言することができます。そして、ローカル変数の有効範囲は宣言したブロックの中になります。これはC言語や Perl と同じです。関数の引数は、関数を実行している間だけ有効です。ブロックから抜けると、そのブロックの中で宣言されたローカル変数は廃棄されます。関数の引数は、関数の実行が終了すると廃棄されます。
●可変個引数
Lua の関数は最後の引数に ... を指定すると、可変個の引数を受け取ることができます。... を可変引数式といいます。多重代入を使うと、可変引数式から複数の値を取り出すことができます。
簡単な例を示します。
> function foo(...) local a, b = ...; print(a); print(b) end > foo() nil nil > foo(1) 1 nil > foo(1, 2) 1 2 > foo(1, 2, 3) 1 2
可変個引数は関数 select を使って操作することができます。
select(index, ...)
select は可変個引数を受け付ける関数で、受け取った 可変個引数の index 番目以降の引数をすべて返します。また、index に文字列 "#" を指定すると、可変個引数の個数を求めることができます。
簡単な例を示しましょう。
> select(1, 10, 20, 30)
10 20 30
> select(2, 10, 20, 30)
20 30
> select(3, 10, 20, 30)
30
> select("#", 10, 20, 30)
3
select は可変引数式を受け取ることができます。可変個引数をひとつずつ取り出す処理は、select を使うと次のようになります。
リスト 3 : 可変個引数の処理 (1)
function foo(...)
for i = 1, select("#", ...) do
local x = select(i, ...)
print(x)
end
end
x = select(i, ...) とすることで、 i 番目の引数を変数 x に取り出すことができます。
簡単な例を示します。
> foo() > foo(1) 1 > foo(1,2) 1 2 > foo(1,2,3) 1 2 3 > foo(1,2,3,4) 1 2 3 4
このほかに、可変引数式を配列に変換する方法もあります。{...} とすると可変引数式の値を配列に格納することができます。また、{select(i, ...)} とすれば、i 番目以降の引数を配列に格納することができます。簡単な例を示します。
> function bar(...) local a = ...; local b = {select(2, ...)}; return a, b end
> bar(1,2,3,4)
1 table: 0x7fffda8dab40
関数 table.unpack を使うと、配列を展開して要素を関数の引数に渡すことができます。簡単な例を示します。
> table.unpack({1,2,3})
1 2 3
> function foo(a, ...) local b, c = ...; print(a); print(b); print(c) end
> foo(unpack({1,2,3}))
1
2
3
●データの探索
それでは簡単な例題として、データの探索処理を作ってみましょう。データの探索とは、あるデータの中から特定のデータを見つける処理のことです。データの探索はプログラムの中で最も基本的な操作のひとつです。ここでは配列の中からデータを探すことを考えます。
いちばん簡単な方法は先頭から順番にデータを比較していくことです。これを「線形探索 (linear searching)」といます。たとえば、配列の中からデータを探す処理はリスト 4 のようになります。
リスト 4 : データの探索
function find(n, ary)
for i = 1, #ary do
if n == ary[i] then
return true
end
end
return false
end
関数 find は配列 ary の中から引数 n と等しいデータを探します。for 文で配列の要素を一つずつ順番にアクセスして n と比較します。等しい場合は true を返します。n と等しい要素が見つからない場合、for ループを終了して false を返します。
見つけた要素の位置が必要な場合は次のようになります。
リスト 5 : 位置を返す
function position(n, ary)
for i = 1, #ary do
if n == ary[i] then
return i
end
end
return -1
end
関数 position は等しいデータを見つけた場合はその位置 i を返し、見つからない場合は -1 を返します。
find と position は最初に見つけた要素とその位置を返しますが、同じ要素が配列に複数個あるかもしれません。そこで、要素の個数を数える関数を作ってみましょう。リスト 6 を見てください。
リスト 6 : 個数を返す
function count(n, ary)
local c = 0
for i = 1, #ary do
if n == ary[i] then
c = c + 1
end
end
return c
end
変数 c を 0 に初期化し、n と等しい要素 x を見つけたら c の値を +1 します。最後に return で c の値を返します。
それでは実際に試してみましょう。
> a = {1,2,3,4,5,1,3,5,3}
> find(3, a)
true
> find(6, a)
false
> position(3, a)
3
> position(6, a)
-1
> count(3, a)
3
> count(6, a)
0
このように、線形探索は簡単にプログラムできますが、大きな欠点があります。データ数が多くなると処理に時間がかかるのです。近年、パソコンの性能は著しく向上しているので、線形探索でどうにかなる場合もありますが、データ数が多くて時間かかかるのであれば、次の例題で取り上げる「二分探索」や他の高速な探索アルゴリズム [*1] を使ってみてください。
[*1] 基本的なところでは、ハッシュの実装に用いられている「ハッシュ法」や「二分探索木」などがあります。
●二分探索
次は「二分探索 (バイナリサーチ:binary searching)」を例題として取り上げます。線形探索の実行時間は要素数 N に比例するので、数が多くなると時間がかかるようになります。これに対し、二分探索は log2 N に比例する時間でデータを探すことができます。
ただし、探索するデータはあらかじめ昇順に並べておく必要があります。この操作を「ソート (sort)」といいます。二分探索は最初にデータをソートしておかないといけないので、線形探索に比べて準備に時間がかかります。
二分探索の動作を図 4 に示します。
図 4 : 二分探索
二分探索は探索する区間を半分に分割しながら調べていきます。キーが 66 の場合を考えてみましょう。まず区間の中央値 55 とキーを比較します。データが昇順にソートされている場合、66 は中央値 55 より大きいので区間の前半を調べる必要はありません。したがって、後半部分だけを探索すればいいのです。
あとは、これと同じことを後半部分に対して行います。最後には区間の要素が一つしかなくなり、それとキーが一致すれば探索は成功、そうでなければ探索は失敗です。ようするに、探索するデータ数が 1 / 2 ずつ減少していくわけです。図 4 の場合、線形探索ではデータの比較が 6 回必要になりますが、二分探索であれば 4 回で済みます。また、データ数が 100 万個になったとしても、二分探索を使えば高々 20 回程度の比較で探索を完了することができます。
それでは、配列からデータを二分探索するプログラムを作ってみましょう。二分探索は繰り返しを使って簡単にプログラムできます。リスト 7 を見てください。
リスト 7 : 二分探索
function binary_search(n, ary)
local low = 1
local high = #ary
while low <= high do
local mid = (low + high) // 2
if n == ary[mid] then
return true
elseif n < ary[mid] then
high = mid - 1
else
low = mid + 1
end
end
return false
end
最初に、探索する区間を示す変数 low と high を初期化します。配列の長さは #ary で取得し、最後の要素の位置を high にセットします。次の while ループで、探索区間を半分ずつに狭めていきます。まず、区間の中央値を求めて mid にセットします。if 文で mid の位置にある要素と x を比較し、等しい場合は探索成功です。return で true を返します。
x が大きい場合は区間の後半を調べます。変数 low に mid + 1 をセットします。逆に、x が小さい場合は前半を調べるため、変数 high に mid - 1 をセットします。これを区間が二分割できるあいだ繰り返します。low が high より大きくなったら分割できないので繰り返しを終了し false を返します。
簡単な実行例を示しましょう。
> a = {11,22,33,44,55,66,77,88,99}
> binary_search(44, a)
true
> binary_search(40, a)
false
二分探索はデータを高速に探索することができますが、あらかじめデータをソートしておく必要があります。このため、途中でデータを追加するには、データを挿入する位置を求め、それ以降のデータを後ろへ移動する処理が必要になります。つまり、データの登録には時間がかかるのです。
したがって、二分探索はプログラムの実行中にデータを登録し、同時に探索も行うという使い方には向いていません。途中でデータを追加して探索も行う場合は、他の高速な探索アルゴリズムを検討してみてください。
●素数を求める (2)
それでは関数を使って、前回作成した素数を求めるプログラムを書き直して見ましょう。リスト 8 を見てください。
リスト 8 : 素数を求める
-- 素数か?
function primep(x, prime_list)
for i = 1, #prime_list do
local y = prime_list[i]
if y * y > x then
break
end
if x % y == 0 then
return false
end
end
return true
end
-- 素数を求める
function prime(n)
local prime_list = {2}
for x = 3, n, 2 do
if primep(x, prime_list) then
table.insert(prime_list, x)
end
end
return prime_list
end
> for i, v in ipairs(prime(100)) do io.write(v); io.write(" ") end
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
数値 x が素数か判定する処理を関数 primep で行うように変更します。primep は数値 x と素数を格納した配列 prime_list を受け取り、x が素数で割り切れれば false を返し、そうでなければ true を返します。
primep を使うと、素数を求める関数 prime は簡単にプログラムすることができます。primep が true を返したら x を prime_list に追加するだけです。素数の判定処理を関数 primep で行うことにより、関数 prime はとてもわかりやすいプログラムになりました。
改訂 2019 年 12 月 28 日
 図 6 : fact の再帰呼び出し(n:引数の値, value:返り値)
図 6 : fact の再帰呼び出し(n:引数の値, value:返り値)
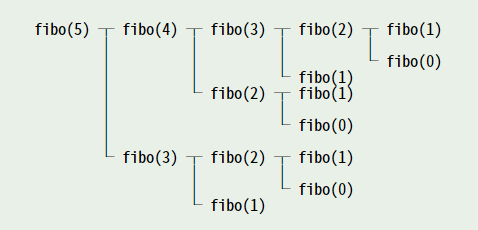 図 9 : 関数 fibo のトレース
図 9 : 関数 fibo のトレース