はじめに
拙作のページ「二分木とヒープ」で説明したヒープ (heap) は、優先度つき待ち行列 (プライオリティキュー : priority queue) の実装でよく使われるデータ構造です。プライオリティキューはとても便利なデータ構造で、拙作のページ「ヒューリスティック探索」では最良優先探索と A* アルゴリズムを実装するときに使いました。このほかに、グラフ理論のアルゴリズムでもプライオリティキューはよく使われています。
今回は MST (Minimum Spanning Tree) を求める「プリムのアルゴリズム」にプライオリティキューを適用して、どのくらい処理を高速化できるか試してみましょう。
●Euclidean MST
MST を求める「プリムのアルゴリズム」と「クラスカルのアルゴリズム」は拙作のページ「欲張り法 [2]」で詳しく説明しました。頂点の個数を N, 辺の総数を E とすると、プリムのアルゴリズムの場合、単純な実装方法だと実行時間は N2 に比例し、クラスカルのアルゴリズムは E * log2 E に比例します。頂点に接続されている辺の本数が少ない場合、クラスカルのアルゴリズムのほうが速いのですが、辺の総数が増えると、プリムのアルゴリズムのほうが速くなる場合もあります。
そこで、辺の総数が多い例として Euclidean MST を取り上げることにします。Euclidean MST は平面上に与えられた N 個の頂点の MST を求める問題です。一つの頂点には N - 1 本の辺が接続されていて、各辺のコストは 2 点間の直線距離 (Euclidean distance) になります。この場合、辺の総数 E は N2 に比例するので、クラスカルのアルゴリズムでは N2 * log2 N に比例する時間がかかることになり、プリムのアルゴリズムよりも遅くなると思われます。
●プログラムの作成
それでは実際にプログラムを作って確かめてみましょう。最初にテストデータを生成する関数 make_data() を作ります。
リスト : データの生成
# 高さと幅
WIDTH = 700
HEIGHT = 500
# データの生成
def make_data(n, s):
random.seed(s)
buff = []
for _ in range(n):
x = random.randint(0, WIDTH) + 20
y = random.randint(0, HEIGHT) + 20
buff.append((x, y))
return buff
make_data() は頂点の座標を乱数で生成します。引数 n が頂点の個数、s が乱数のシードです。s が同じ値ならば、同じ乱数列が生成されます。大域変数 WIDTH が幅、HEIGHT が高さを表します。Tkinter で描画することを考慮して、座標は (20, 20) - (WIDTH + 20, HEIGHT + 20) の範囲で生成します。生成したデータは大域変数 point_table にセットされます。
プログラムは次のようになります。
リスト : Euclidean MST
# 距離の計算
def dis(p1, p2):
dx = p1[0] - p2[0]
dy = p1[1] - p2[1]
return int(math.sqrt(dx * dx + dy * dy) + 0.5)
# 辺の定義
class Edge:
def __init__(self, p1, p2, weight):
self.p1 = p1
self.p2 = p2
self.weight = weight # 整数値
def __gt__(x, y): return x.weight > y.weight
def __le__(x, y): return x.weight <= y.weight
# クラスカルのアルゴリズム
def kruskal(size):
q = pqueue.PQueue()
s = []
u = UnionFind(size)
# 辺をヒープに追加
for i in range(size - 1):
for j in range(i + 1, size):
q.push(Edge(i, j, dis(point_table[i], point_table[j])))
i = 0
while i < size - 1:
e = q.pop()
if u.find(e.p1) != u.find(e.p2):
u.union(e.p1, e.p2)
s.append(e)
i += 1
return s
# プリムのアルゴリズム
def prim(size):
closest = [0] * size
low_cost = [0] * size
s = []
# 初期化
for i in range(size):
low_cost[i] = dis(point_table[0], point_table[i])
# 頂点の選択
for i in range(1, size):
min = low_cost[1]
k = 1
for j in range(2, size):
if min > low_cost[j]:
min = low_cost[j]
k = j
s.append(Edge(k, closest[k], min))
low_cost[k] = INF
for j in range(1, size):
l = dis(point_table[k], point_table[j])
if low_cost[j] < INF and low_cost[j] > l:
low_cost[j] = l
closest[j] = k
return s
関数 dis() は 2 点間の距離を計算して整数値に変換して返します。0.5 を加算しているのは小数点第 1 位で四捨五入するためです。クラスカルのアルゴリズムはモジュール pqueue と unionfind を使っています。最初にすべての辺をプライオリティキューに登録し、短い辺から順番に取り出していきます。 UnionFind のメソッド find で閉路ができないことを確認し、選んだ辺を配列 s に追加します。N - 1 本の辺を選んだら配列 s を return で返します。
プリムのアルゴリズムも簡単です。low_cost に最小のコストを、closest に最小のコストになる頂点を記憶します。最初、closest は 0 に、low_cost は 0 と他の頂点の距離に初期化します。あとは、low_cost の中で最小値の頂点 k を選び、辺 Edge を生成して配列 s に追加します。そして、low_cost と closest の値を更新します。最後に選択した辺を格納した配列 s を返します。
あとのプログラムは簡単なので説明は割愛します。詳細はプログラムリスト1をお読みください。
●実行結果
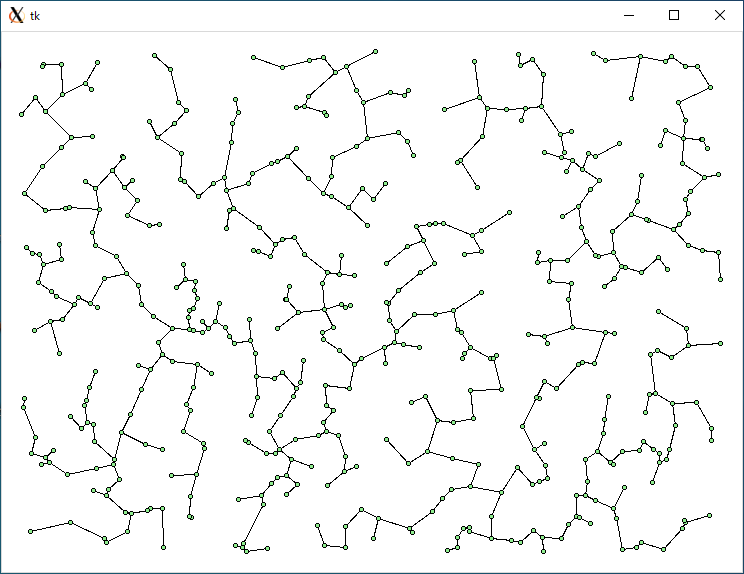 N = 500
N = 500
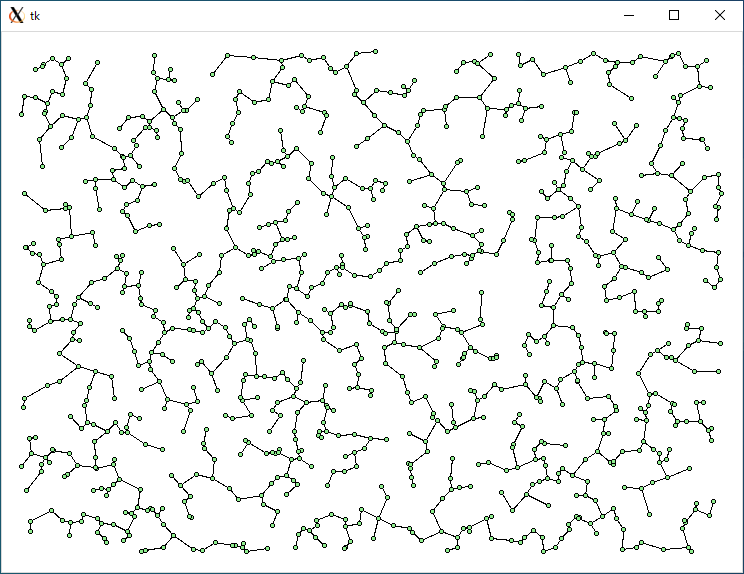 N = 1000
N = 1000
 N = 1500
N = 1500
 N = 2000
N = 2000
それでは実行してみましょう。乱数で適当に作成したデータ (シード s = 1, 個数 n = 500, 1000, 1500, 2000) の場合、結果は上図のようになりました。
表 : 実行結果 (単位 秒)
個数 : 距離 : krus : prim
------+-------+---------------+---------------
500 : 8715 : 0.37 ( 1.00) : 0.19 ( 1.00)
1000 : 12193 : 1.62 ( 4.38) : 0.70 ( 3.68)
1500 : 14948 : 3.60 ( 9.72) : 1.63 ( 8.57)
2000 : 17292 : 6.53 (17.64) : 2.97 (15.63)
krus: クラスカルのアルゴリズム
prim: プリムのアルゴリズム
実行環境 : Python 3.8.10, Ubuntu 20.04 LTS (WSL1), Intel Core i5-6200U 2.30GHz
結果を見ればおわかりのように、プリムのアルゴリズムのほうが高速になりました。500 個の実行時間を 1.00 とすると、プリムのアルゴリズムがだいたい N2 に比例しているのに対し、クラスカルのアルゴリズムはそれ以上の時間がかかっていることがわかります。
●プリムのアルゴリズムの改良
プリムのアルゴリズムはプライオリティキューを使って改良することができます。一番簡単な方法は、頂点を選択したとき、それにつながる辺をすべてプライオリティキューに追加することです。次のリストを見てください。
リスト : プリムのアルゴリズム (改良版)
def prim0(size):
q = pqueue.PQueue()
v = [False] * size
s = []
q.push(Edge(0, 0, 0))
#
i = 0
while i < size:
e = q.pop()
if v[e.p2]: continue
v[e.p2] = True
s.append(e)
# e.p2 につながる辺を追加
for j in range(size):
if not v[j]:
q.push(Edge(e.p2, j, dis(point_table[e.p2], point_table[j])))
i += 1
return s[1:]
プライオリティキューは変数 q にセットします。配列 v は頂点を選択したとき True をセットします。最初は False に初期化します。配列 s は選んだ辺を格納します。最初、ダミーで頂点 0 から 0 までの辺 (長さ 0) をキューにセットします。そして、while ループでダミーの辺を入れて size 本の辺を選択します。
頂点の選択は簡単です。キューから辺を pop() で取り出します。辺 e を生成する場合、辺の両端 p1, p2 のうち p1 は選択済みの頂点、p2 は未選択の頂点、weight が p1 から p2 までの距離とします。キューから辺を取り出したとき、p2 は既に選択されている場合があるので、それを v[e.p2] でチェックします。False の場合、頂点 e.p2 を選択して、辺を s に追加します。そして、e.p2 につながる辺の中で、未選択の頂点につながる辺をすべてキューに追加します。
この方法は辺をすべてキューに追加することになるので、実行時間はクラスカルのアルゴリズムと同じく E * log2 E となります。辺の総数が少ない場合、クラスカルのアルゴリズムと同じく高速に動作しますが、辺の総数が増えると遅くなってしまいます。そこで、各頂点の最短距離を配列に格納しておいて、それよりも短い辺をキューに追加することにします。
プログラムは次のようになります。
リスト : プリムのアルゴリズム (改良版1)
def prim1(size):
q = pqueue.PQueue()
v = [False] * size
d = [INF] * size
s = []
q.push(Edge(0, 0, 0))
#
i = 0
while i < size:
e = q.pop()
if v[e.p2]: continue
v[e.p2] = True
s.append(e)
# e.p2 につながる辺を追加
for j in range(size):
if not v[j]:
l = dis(point_table[e.p2], point_table[j])
if l < d[j]:
d[j] = l
q.push(Edge(e.p2, j, l))
i += 1
return s[1:]
配列 d に各頂点の最短距離を格納します。最初は INF (999999999) で処理化します。そして、辺 e.p2 - j をキューに追加するとき、距離を計算して変数 l にセットします。l < d[j] であれば d[j] を l に書き換えて、辺 e.p2 - j をキューに追加します。これで、プライオリティキューに追加される辺の個数が抑えれれるので、実行速度も速くなると思われます。
●実行結果 (2)
それでは実行してみましょう。
表 : 実行結果 (単位 秒)
個数 : 距離 : krus : prim : prim0 : prim1
------+-------+------+------+-------+-------
500 : 8715 : 0.37 : 0.19 : 0.37 : 0.15
1000 : 12193 : 1.62 : 0.70 : 1.60 : 0.55
1500 : 14948 : 3.60 : 1.63 : 3.64 : 1.02
2000 : 17292 : 6.53 : 2.97 : 6.53 : 1.83
krus : クラスカルのアルゴリズム prim : プリムのアルゴリズム prim0: プリムのアルゴリズム (改良版) prim1: プリムのアルゴリズム (改良版1)
prim0 はクラスカルのアルゴリズムとだいたい同じくらいで、実行時間は prim よりも遅くなりました。辺の総数が少なければ prim よりも速くなると思います。prim1 は prim よりも速くなりました。
ところで、プリムのアルゴリズムは選択済みの頂点から最短距離の頂点を選べばいいのですから、プライオリティキューに格納するのは未選択の頂点と最短距離でいいはずです。そうすると、キューの大きさは最大で N に抑えることができます。ただし、キューにあるデータの最短距離を書き換える、つまり優先順位 (プライオリティ) を変更する操作が必要になります。この操作を「キー値の減算 (decrease key)」といいます。
プリム法 - Wikipedia によると、decrease key の操作が log2 N に比例する時間で実行できる場合、プリムのアルゴリズムは (N + E) * log2 N => E * log2 N に比例する時間で実行することができる、とのことです。
●キー値の減算処理
それではプライオリティキューにメソッド decrease_key(x, d) を追加しましょう。x はキューに格納するオブジェクト、d がキーから減算する値です。配列に格納されているオブジェクト x の位置 (添字) がわかれば、プライオリティの変更操作は log2 N に比例する時間で行うことができます。そこで、オブジェクトの位置 (添字) を辞書に格納しておくことにします。
プログラムは次のようになります。
リスト : プライオリティキュー (decrease_key の追加)
# 葉の方向へ
def _downheap(buff, n, idx):
size = len(buff)
while True:
c = 2 * n + 1
if c >= size: break
if c + 1 < size:
if not buff[c] <= buff[c + 1]: c += 1
if buff[n] <= buff[c]: break
temp = buff[n]
buff[n] = buff[c]
buff[c] = temp
idx[buff[c]] = c
idx[buff[n]] = n
n = c
# 根の方向へ
def _upheap(buff, n, idx):
while True:
p = (n - 1) / 2
if p < 0 or buff[p] <= buff[n]: break
temp = buff[n]
buff[n] = buff[p]
buff[p] = temp
idx[buff[n]] = n
idx[buff[p]] = p
n = p
class PQueue:
def __init__(self, buff = []):
self.buff = buff[:] # コピー
self.idx = {}
for x in range(len(buff)):
self.idx[buff[x]] = x
for n in range(len(self.buff) / 2 - 1, -1, -1):
_downheap(self.buff, n, self.idx)
# 最小値を取り出す
def pop(self):
if len(self.buff) == 0: raise IndexError
value = self.buff[0]
del self.idx[value]
last = self.buff.pop()
if len(self.buff) > 0:
# ヒープの再構築
self.buff[0] = last
self.idx[last] = 0
_downheap(self.buff, 0, self.idx)
return value
# データの挿入
def push(self, data):
self.buff.append(data)
self.idx[data] = len(self.buff) - 1
_upheap(self.buff, len(self.buff) - 1, self.idx)
# 最小値を求める
def peek(self): return self.buff[0]
# 空か
def isEmpty(self): return len(self.buff) == 0
# 格納されているデータを返す
def content(self): return self.buff
# キー値の減算
def decrease_key(self, x, d):
x.decrease_key(d)
if d > 0:
_upheap(self.buff, self.idx[x], self.idx)
else:
_downheap(self.buff, self.idx[x], self.idx)
関数 _upheap(), _downheap() の引数 idx はオブジェクトの添字を格納する辞書です。オブジェクトを移動したら、idx にその位置をセットします。__init__() では、オブジェクトを配列に格納して与えられたとき、オブジェクトの位置を idx にセットする処理を追加します。
メソッド pop() はオブジェクトを削除したとき、idx のデータも削除するようにします。最後尾のデータを先頭に移動したとき、idx の値も書き換えることに注意してください。メソッド push() も簡単です。配列の最後尾に data を追加したとき、idx にその位置をセットします。メソッド content() はデータを格納している配列 buff を返します。
x の位置がわかると、メソッド decrease_key() は簡単です。最初に、オブジェクト x のメソッド decrease_key() を呼び出して、キーの値から d を減算します。次に、d の値が正であればキーの値は減少しているので、_upheap() を呼び出してオブジェクト x がヒープの条件を満たすように修正します。逆に、d が負の値であればキーの値は増加しているので _downheap() を呼び出して x の位置を修正します。
このように辞書の操作が加わるため、今までよりも push(), pop() の操作が遅くなるのは仕方がありません。decrease_key の操作が必要ない場合は、今までのプライオリティキューを使ったほうがよいでしょう。
●簡単なテスト
それではここで decrease_key の簡単なテストを行ってみましょう。次のリストを見てください。
リスト : 簡単なテスト
if __name__ == '__main__':
class Num:
def __init__(self, n):
self.n = n
def __gt__(x, y): return x.n > y.n
def __le__(x, y): return x.n <= y.n
def decrease_key(self, d):
self.n -= d
def __str__(self):
return "(%d)" % self.n
def __hash__(self):
return id(self)
a = [Num(x) for x in range(10)]
q = PQueue(a)
for x in range(10):
print(x, ":", q.peek(), a[x], end=' ')
q.decrease_key(a[x], 20)
print(q.peek(), a[x], end=' ')
q.decrease_key(a[x], -20)
print(q.peek(), a[x])
while not q.isEmpty():
print(q.pop(), end=' ')
print()
整数値を格納するクラス Num を定義します。この中で必要な特殊メソッド __lt__(), __ge__(), __hash__() とメソッド decrease_key() を定義します。辞書にオブジェクトを格納する場合、__hash__() の定義が必要になります。
テストは簡単で、0 - 9 を格納した Num のオブジェクトを生成してキューに追加します。そして a[x] のデータを decrease_key で -20 したあと、+20 して元に戻します。そのとき、peek() で最小値を求めて表示します。実行結果は次のようになります。
0 : (0) (0) (-20) (-20) (0) (0) 1 : (0) (1) (-19) (-19) (0) (1) 2 : (0) (2) (-18) (-18) (0) (2) 3 : (0) (3) (-17) (-17) (0) (3) 4 : (0) (4) (-16) (-16) (0) (4) 5 : (0) (5) (-15) (-15) (0) (5) 6 : (0) (6) (-14) (-14) (0) (6) 7 : (0) (7) (-13) (-13) (0) (7) 8 : (0) (8) (-12) (-12) (0) (8) 9 : (0) (9) (-11) (-11) (0) (9) (0) (1) (2) (3) (4) (5) (6) (7) (8) (9)
a[0] の値は 0 で、それが最小値になります。0 から 20 減算すると、最小値は -20 になり、a[0] の値も -20 になります。20 を加算すると元の値に戻ります。次に、a[1] の値は 1 で最小値は 0 です。1 から 20 減算すると、最小値は -19 になり、a[1] の値も -19 になります。20 を加算すると元の値に戻り、最小値も 0 になります。あとは同じ動作で、最後にデータを pop() で取り出していくと、小さな値から順番に出力されます。
●プリムのアルゴリズムの改良 (2)
それでは decrease_key を使ってプリムのアルゴリズムを改良しましょう。次のリストを見てください。
リスト : プリムのアルゴリズム (改良版2)
# 辺の定義
class Edge:
def __init__(self, p1, p2, weight):
self.p1 = p1
self.p2 = p2
self.weight = weight # 整数値
def decrease_key(self, x):
self.weight -= x
def __gt__(x, y): return x.weight > y.weight
def __le__(x, y): return x.weight <= y.weight
def __hash__(self):
return id(self)
# プリムのアルゴリズム (E * log N)
def prim2(size):
q = pqueuedk.PQueue()
s = []
for i in range(1, size):
q.push(Edge(0, i, dis(point_table[0], point_table[i])))
#
while not q.isEmpty():
e = q.pop()
s.append(e)
for x in q.content():
l = dis(point_table[e.p2], point_table[x.p2])
if l < x.weight:
# 値の書き換え
x.p1 = e.p2
q.decrease_key(x, x.weight - l)
return s
クラス Edge にはメソッド decrease_key() と __hash__() を追加します。関数 prim2() は、最初に頂点 0 と他の頂点を結ぶ辺を生成し、それをプライオリティキュー q にセットします。あとは、キューからデータを取り出して、decrease_key() でキーの値を書き換えていくだけです。このとき、キューに残っているデータがまだ選択していない頂点になります。メソッド content() でキュー内のデータを取り出し、距離を比較して値が小さければ、辺の値を書き換えます。
decrease_key() を実行すると、データ x が配列の前方へ移動し、配列の値が書き換えられます。x よりも前にあるデータはチェック済みなので、for 文の中で配列の値を書き換えても問題なく動作します。逆に、x よりも後ろにあるデータと交換する場合は正常に動作しません。ご注意ください。
●実行結果 (3)
それでは実行してみましょう。結果は次のようになりました。
表 : 実行結果 (単位 秒)
個数 : 距離 : krus : prim : prim0 : prim1 : prim2
------+-------+------+------+-------+-------+-------
500 : 8715 : 0.37 : 0.19 : 0.37 : 0.15 : 0.12
1000 : 12193 : 1.62 : 0.70 : 1.60 : 0.55 : 0.42
1500 : 14948 : 3.60 : 1.63 : 3.64 : 1.02 : 0.94
2000 : 17292 : 6.53 : 2.97 : 6.53 : 1.83 : 1.64
decrease_key を使うことで、prim, prim1 よりも速くなりました。辺の総数が多い Euclidean MST の場合、decrease_key の効果は大きいようです。辺の総数が少ない場合、prim1 で十分かもしれません。
なお、これらの結果は M.Hiroi のコーディング、実行したマシン、プログラミング言語などの環境に大きく依存しています。また、これらの環境だけではなく、データの種類によっても実行時間はかなり左右されます。興味のある方は、いろいろなデータをご自分の環境で試してみてください。
●プログラムリスト1
#
# emst.py : ユークリッド距離による MST
#
# Copyright (C) 2012-2022 Makoto Hiroi
#
import sys, math, time. random
import pqueue
import pqueuedk
from unionfind import *
from tkinter import *
# 無限大
INF = 999999999
# 高さと幅
WIDTH = 700
HEIGHT = 500
# データの生成
def make_data(n, s):
random.seed(s)
buff = []
for _ in range(n):
x = random.randint(0, WIDTH) + 20
y = random.randint(0, HEIGHT) + 20
buff.append((x, y))
return buff
# 距離の計算
def dis(p1, p2):
dx = p1[0] - p2[0]
dy = p1[1] - p2[1]
return int(math.sqrt(dx * dx + dy * dy) + 0.5)
# 距離の計算
def edge_length(select_edge):
n = 0
for e in select_edge:
n += e.weight
return n
#
# 辺の定義
#
class Edge:
def __init__(self, p1, p2, weight):
self.p1 = p1
self.p2 = p2
self.weight = weight # 整数値
def decrease_key(self, x):
self.weight -= x
def __gt__(x, y): return x.weight > y.weight
def __le__(x, y): return x.weight <= y.weight
def __hash__(self):
return id(self)
#
# クラスカルのアルゴリズム
#
def kruskal(size):
q = pqueue.PQueue()
s = []
u = UnionFind(size)
# 辺をヒープに追加
for i in range(size - 1):
for j in range(i + 1, size):
q.push(Edge(i, j, dis(point_table[i], point_table[j])))
i = 0
while i < size - 1:
e = q.pop()
if u.find(e.p1) != u.find(e.p2):
u.union(e.p1, e.p2)
s.append(e)
i += 1
return s
#
# プリムのアルゴリズム
#
def prim(size):
closest = [0] * size
low_cost = [0] * size
s = []
# 初期化
for i in range(size):
low_cost[i] = dis(point_table[0], point_table[i])
# 頂点の選択
for i in range(1, size):
min = low_cost[1]
k = 1
for j in range(2, size):
if min > low_cost[j]:
min = low_cost[j]
k = j
s.append(Edge(k, closest[k], min))
low_cost[k] = INF
for j in range(1, size):
l = dis(point_table[k], point_table[j])
if low_cost[j] < INF and low_cost[j] > l:
low_cost[j] = l
closest[j] = k
return s
def prim0(size):
q = pqueue.PQueue()
v = [False] * size
s = []
q.push(Edge(0, 0, 0))
#
i = 0
while i < size:
e = q.pop()
if v[e.p2]: continue
v[e.p2] = True
s.append(e)
# e.p2 につながる辺を追加
for j in range(size):
if not v[j]:
q.push(Edge(e.p2, j, dis(point_table[e.p2], point_table[j])))
i += 1
return s[1:]
def prim1(size):
q = pqueue.PQueue()
v = [False] * size
d = [INF] * size
s = []
q.push(Edge(0, 0, 0))
#
i = 0
while i < size:
e = q.pop()
if v[e.p2]: continue
v[e.p2] = True
s.append(e)
# e.p2 につながる辺を追加
for j in range(size):
if not v[j]:
l = dis(point_table[e.p2], point_table[j])
if l < d[j]:
d[j] = l
q.push(Edge(e.p2, j, l))
i += 1
return s[1:]
def prim2(size):
q = pqueuedk.PQueue()
s = []
for i in range(1, size):
q.push(Edge(0, i, dis(point_table[0], point_table[i])))
#
while not q.isEmpty():
e = q.pop()
s.append(e)
for x in q.content():
l = dis(point_table[e.p2], point_table[x.p2])
if l < x.weight:
# 値の書き換え
x.p1 = e.p2
q.decrease_key(x, x.weight - l)
return s
#
# 実行
#
point_table = make_data(2000, 1)
point_size = len(point_table)
s = time.time()
es = kruskal(point_size)
print(edge_length(es))
print(time.time() - s)
s = time.time()
es = prim(point_size)
print(edge_length(es))
print(time.time() - s)
s = time.time()
es = prim0(point_size)
print(edge_length(es))
print(time.time() - s)
s = time.time()
es = prim1(point_size)
print(edge_length(es))
print(time.time() - s)
s = time.time()
es = prim2(point_size)
print(edge_length(es))
print(time.time() - s)
#
# 経路の表示
#
# 辺の表示
def draw_edge(edge):
global point_table
for e in edge:
x0, y0 = point_table[e.p1]
x1, y1 = point_table[e.p2]
id = c0.create_line(x0, y0, x1, y1)
# 都市の表示
def draw_point():
for x, y in point_table:
c0.create_oval(x - 2, y - 2, x + 2, y + 2, fill = "lightgreen")
root = Tk()
c0 = Canvas(root, width = WIDTH + 40, height = HEIGHT + 40, bg = "white")
c0.pack()
draw_edge(es)
draw_point()
root.mainloop()
●プログラムリスト2
#
# pqueuedk.py : 優先度つき待ち行列 (decrease_key をサポート)
#
# Copyright (C) 2012-2022 Makoto Hiroi
#
# 葉の方向へ
def _downheap(buff, n, idx):
size = len(buff)
while True:
c = 2 * n + 1
if c >= size: break
if c + 1 < size:
if not buff[c] <= buff[c + 1]: c += 1
if buff[n] <= buff[c]: break
temp = buff[n]
buff[n] = buff[c]
buff[c] = temp
idx[buff[c]] = c
idx[buff[n]] = n
n = c
# 根の方向へ
def _upheap(buff, n, idx):
while True:
p = (n - 1) // 2
if p < 0 or buff[p] <= buff[n]: break
temp = buff[n]
buff[n] = buff[p]
buff[p] = temp
idx[buff[n]] = n
idx[buff[p]] = p
n = p
class PQueue:
def __init__(self, buff = []):
self.buff = buff[:] # コピー
self.idx = {}
for x in range(len(buff)):
self.idx[buff[x]] = x
for n in range(len(self.buff) // 2 - 1, -1, -1):
_downheap(self.buff, n, self.idx)
# 最小値を取り出す
def pop(self):
if len(self.buff) == 0: raise IndexError
value = self.buff[0]
del self.idx[value]
last = self.buff.pop()
if len(self.buff) > 0:
# ヒープの再構築
self.buff[0] = last
self.idx[last] = 0
_downheap(self.buff, 0, self.idx)
return value
# データの挿入
def push(self, data):
self.buff.append(data)
self.idx[data] = len(self.buff) - 1
_upheap(self.buff, len(self.buff) - 1, self.idx)
# 最小値を求める
def peek(self): return self.buff[0]
# 空か
def isEmpty(self): return len(self.buff) == 0
# 格納されているデータを返す
def content(self): return self.buff
# キー値の減算
def decrease_key(self, x, d):
x.decrease_key(d)
if d > 0:
_upheap(self.buff, self.idx[x], self.idx)
else:
_downheap(self.buff, self.idx[x], self.idx)
# 簡単なテスト
if __name__ == '__main__':
class Num:
def __init__(self, n):
self.n = n
def __gt__(x, y): return x.n > y.n
def __le__(x, y): return x.n <= y.n
def decrease_key(self, d):
self.n -= d
def __str__(self):
return "(%d)" % self.n
def __hash__(self):
return id(self)
a = [Num(x) for x in range(10)]
q = PQueue(a)
for x in range(10):
print(x, ":", q.peek(), a[x], end=' ')
q.decrease_key(a[x], 20)
print(q.peek(), a[x], end=' ')
q.decrease_key(a[x], -20)
print(q.peek(), a[x])
while not q.isEmpty():
print(q.pop(), end=' ')
print()