はじめに
今回は最短経路を求める「ダイクストラ (Dijkstra) のアルゴリズム」にプライオリティキューを適用し、処理の高速化に挑戦してみましょう。
●最短経路の探索
ダイクストラのアルゴリズムは拙作のページ「欲張り法」で詳しく説明しました。ダイクストラのアルゴリズムを使うと、出発点から全ての頂点に対する最小コストの経路を求めることができます。この問題は「出発点が一つの最短経路問題」と呼ばれています。ゴールが指定されいる場合、つまり 2 つの頂点間の最短経路を求めるだけでよければ、「A* アルゴリズム」を用いることができます。A* アルゴリズムは拙作のページ「ヒューリスティック探索」で詳しく説明しています。
ダイクストラのアルゴリズムを単純な方法で実装した場合、頂点の個数を N とすると、その実行時間は N2 に比例します。辺の総数 E が N2 よりもずっと少ない場合、プライオリティキューを使うことで実行速度を改善することができます。そこで、簡単な例題として辺のコストを距離とし、左上にある頂点から右下にある頂点までの最短経路を求めて、実行速度がどの程度改善されるか確かめてみましょう。
●隣接行列の作成
頂点は前回作成した関数 make_data() で作成します。このデータから隣接行列と隣接リストを作成します。次のリストを見てください。
リスト : 隣接行列の作成
def make_adj(n, ps):
size = len(ps)
dt = [[INF] * size for _ in range(size)]
adj = [[] for _ in range(size)]
cnt = 0
for i in range(size):
tmp = [(j, dis(ps[i], ps[j])) for j in range(size)]
tmp.sort(lambda x, y: x[1] - y[1])
# 短いほうから適当に n 個隣接行列に登録
for j in range(1, n + 1):
k, d = tmp[random.randint(1, 21)]
if dt[i][k] == INF:
dt[i][k] = d
dt[k][i] = d
adj[i].append(k)
adj[k].append(i)
cnt += 1
return dt, adj, cnt
dt が隣接行列、adj が隣接行列、cnt が辺の総数です。INF (999999999) は接続されていないことを表すデータです。ps は頂点の位置 (タプル) を格納した配列です。関数 make_adj() は、頂点 i に近い頂点を適当に n 個選び、それを dt と adj に追加します。1 つの頂点に接続される辺が必ず n 本になるわけではありませんが、簡単な例題なのでこれで良しとしましょう。
●プログラムの作成
それではプログラムを作りましょう。ダイクストラのアルゴリズムを単純な方法で実装すると次のようになります。
リスト : 最短経路の探索
# 経路を作る
def make_path(start, n, prev):
if start == n:
return [start]
else:
return make_path(start, prev[n], prev) + [n]
# ダイクストラ法 (単純版)
def dijk(start, goal, size):
cost = [INF] * size
prev = [None] * size
visited = [False] * size
prev[start] = start
cost[start] = 0
s = start
for _ in range(size):
min_cost = INF
next = -1
visited[s] = True
# 頂点の選択
for i in range(size):
if visited[i]: continue
if dt[s][i] < INF:
d = cost[s] + dt[s][i]
if d < cost[i]:
cost[i] = d
prev[i] = s
if min_cost > cost[i]:
min_cost = cost[i]
next = i
s = next
#
return make_path(start, goal, prev)
visited は選択した頂点を記憶するために使用します。cost は出発点から各頂点への最小コストを格納します。出発点から各頂点への経路を再現するために配列 prev を用意します。この配列には一つ手前の頂点を格納します。prev に格納された頂点を逆にたどっていけば、各頂点の経路を求めることができます。あとは for ループの中で最小コストの頂点を選び、cost と prev を更新するだけです。
●ダイクストラのアルゴリズムの改良
次はプライオリティキューを使ってダイクストラのアルゴリズムを改良してみましょう。最初に、頂点とそのコストを格納するクラスを定義します。
リスト : 頂点とコストの定義
class VCost:
def __init__(self, p, cost):
self.p = p
self.cost = cost # 整数値
def decrease_key(self, x):
self.cost -= x
def __gt__(x, y): return x.cost > y.cost
def __le__(x, y): return x.cost <= y.cost
クラス VCost のインスタンス変数 p が頂点を表す番号、cost がコストを表します。キー値の減算を行わない場合、メソッド decrease_key() は必要ありません。
プライオリティキューを使ったプログラムは次のようになります。
リスト : 最短経路の探索 (改良版 1)
def dijk1(start, goal, size):
cost = [INF] * size
prev = [None] * size
visited = [False] * size
cost[start] = 0
#
pq = pqueue.PQueue()
pq.push(VCost(start, cost[start]))
i = 0
while i < size:
v = pq.pop()
if visited[v.p]: continue
visited[v.p] = True
for x in adj[v.p]:
if cost[x] > v.cost + dt[v.p][x]:
cost[x] = v.cost + dt[v.p][x]
prev[x] = v.p
pq.push(VCost(x, cost[x]))
i += 1
#
return make_path(start, goal, prev)
最初に start の地点を選び、それをキューに追加します。それから while ループで size 個の頂点を選択します。まず、キューからデータ v を取り出し、それが未選択の頂点であることを確認します。次に、隣接リストから隣の頂点 x を求め、cost[x] よりも v.cost + dt[v.p][x] が小さければ、cost[x] と prev[x] の値を更新し、キューに新しいデータを追加します。最後に、関数 make_path() で最短経路を作成して返します。
キー値の減算を使う場合は次のようになります。
リスト ; 最短経路の探索 (改良版 2)
def dijk2(start, goal, size):
cost = [VCost(i, INF) for i in range(size)]
prev = [None] * size
#
cost[start].cost = 0
pq = pqueuedk.PQueue()
pq.push(cost[start])
for _ in range(size):
v = pq.pop()
for x in adj[v.p]:
if cost[x].cost == INF:
cost[x].cost = v.cost + dt[v.p][x]
prev[x] = v.p
pq.push(cost[x])
elif cost[x].cost > v.cost + dt[v.p][x]:
d = cost[x].cost - (v.cost + dt[v.p][x])
prev[x] = v.p
pq.decrease_key(cost[x], d)
#
return make_path(start, goal, prev)
最初に VCost のインスタンスを生成して、配列 cost に格納します。そして、start 地点のインスタンスをキューに登録します。次の for ループでキューからデータを取り出し、隣接している頂点 x の cost と prev を更新します。cost[x].cost が INF と等しい場合、cost[x] はキューに登録されていないので、cost と prev を更新してからキューに登録します。
cost[x].cost よりも v.cost + dt[v.p][x] が小さい場合は、cost[x].cost と prev[x] の値を更新します。そして、decrease_key() でキューにあるデータの優先順位を変更します。最初にインスタンスをすべてキューに登録してもいいのですが、実行時間が遅くなったので今回のようにプログラムしました。
あとのプログラムは簡単なので説明は割愛します。詳細はプログラムリスト1をお読みください。
●実行結果
それでは実行してみましょう。乱数で適当に作成したデータ (500 個, 1000 個, 1500 個) で 1 頂点につながる辺の本数を 3, 5, 7 と指定した場合、結果は次のようになりました。
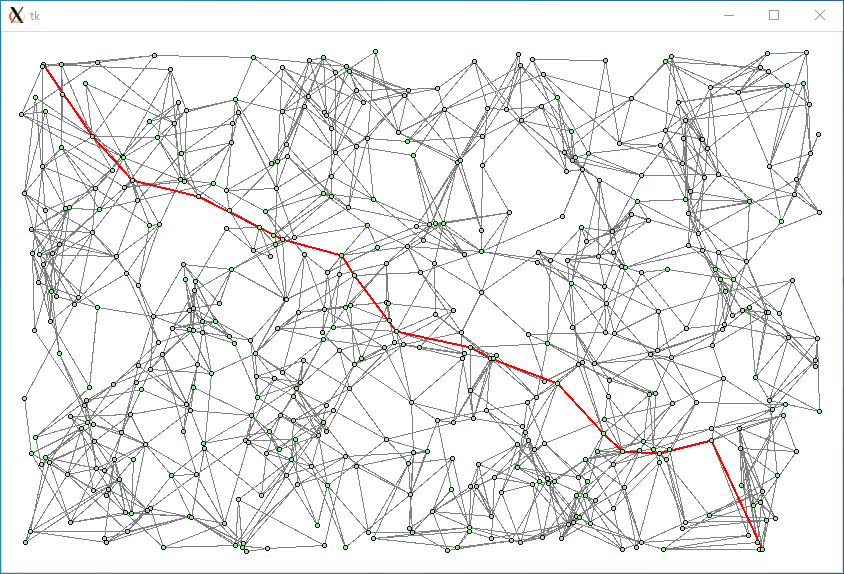 頂点 = 500, 辺 = 3
頂点 = 500, 辺 = 3
 頂点 = 500, 辺 = 5
頂点 = 500, 辺 = 5
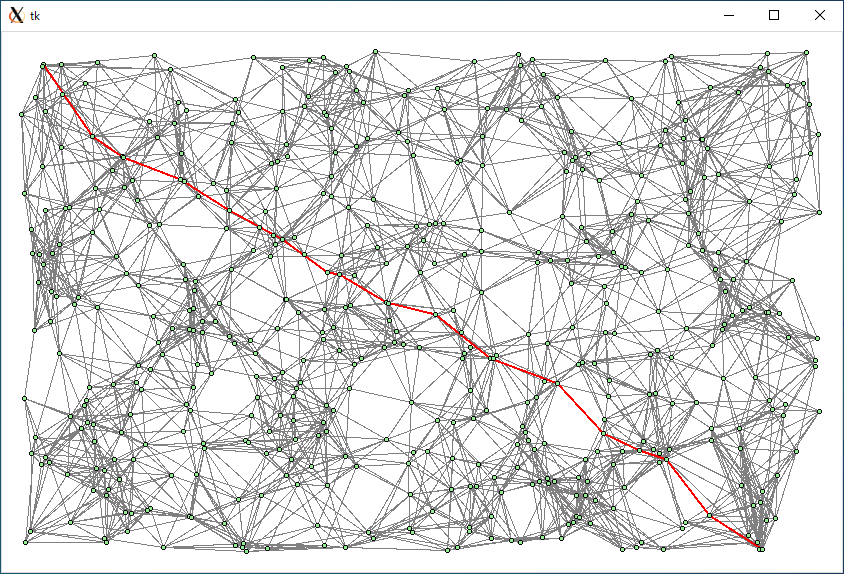 頂点 = 500, 辺 = 7
頂点 = 500, 辺 = 7
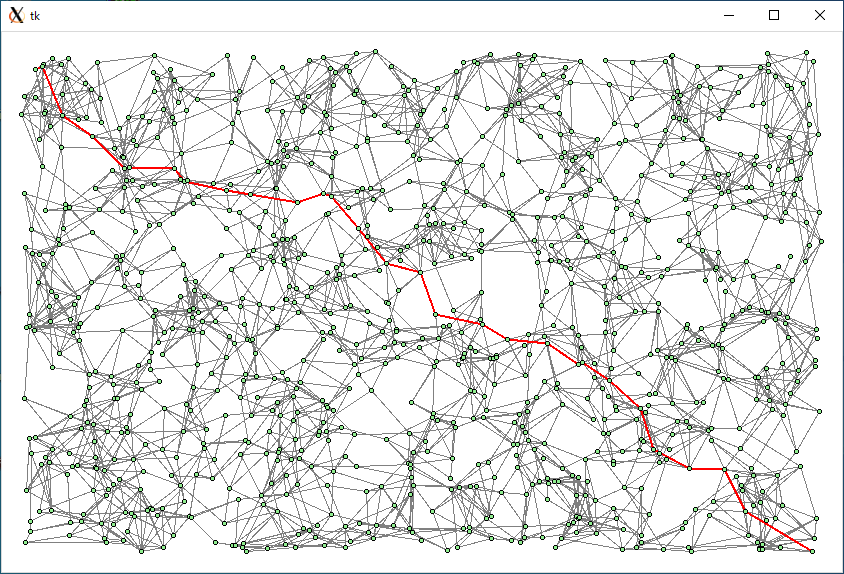 頂点 = 1000, 辺 = 3
頂点 = 1000, 辺 = 3
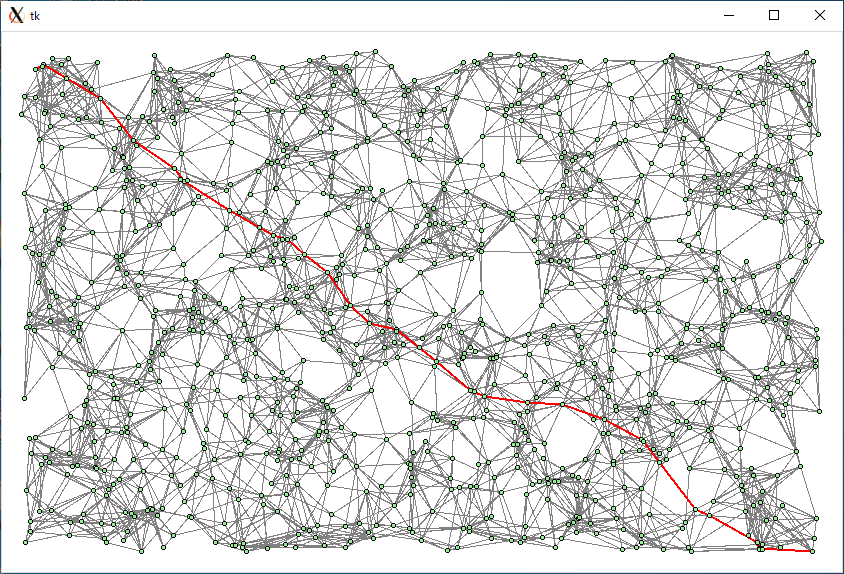 頂点 = 1000, 辺 = 5
頂点 = 1000, 辺 = 5
 頂点 = 1000, 辺 = 7
頂点 = 1000, 辺 = 7
 頂点 = 1500, 辺 = 3
頂点 = 1500, 辺 = 3
 頂点 = 1500, 辺 = 5
頂点 = 1500, 辺 = 5
 頂点 = 1500, 辺 = 7
頂点 = 1500, 辺 = 7
表 : 実行結果 (単位 ミリ秒)
頂点 = 500
辺 : 距離 : dijk : dijk1 : dijk2
---------+------+-------+-------+-------
3 (1347) : 939 : 22.46 : 3.99 : 5.22
5 (2064) : 920 : 23.44 : 5.29 : 5.80
7 (2681) : 888 : 24.88 : 5.87 : 6.07
頂点 = 1000 辺 : 距離 : dijk : dijk1 : dijk2 ---------+------+-------+-------+------- 3 (2688) : 1004 : 98.00 : 8.25 : 9.75 5 (4101) : 952 : 96.73 : 9.29 : 11.42 7 (5293) : 931 : 93.99 : 11.02 : 12.36
頂点 = 1500 辺 : 距離 : dijk : dijk1 : dijk2 ---------+------+-------+-------+------- 3 (4024) : 978 : 237.9 : 12.06 : 15.27 5 (6143) : 958 : 210.3 : 14.93 : 17.62 7 (7950) : 924 : 213.6 : 16.03 : 17.22
dijk : ダイクストラのアルゴリズム (単純版) dijk1 : ダイクストラのアルゴリズム (改良版1) dijk2 : ダイクストラのアルゴリズム (改良版2)
実行環境 : Python 3.8.10, Ubuntu 20.04 LTS (WSL1), Intel Core i5-6200U 2.30GHz
実行時間の単位はミリ秒です。近年のパソコンは高性能なので、今回のデータ数ではあっというまにプログラムの実行は終了します。そこで、各関数を 10 回繰り返した時間を計測し、それを 1 / 10 にしています。
単純な実装方法 (dijk) よりもプライオリティキューを使った改良版 (dijk1, dijk2) のほうが速くなりました。前回の Euclidean MST と違って今回は辺の本数が少ないので、キー値の減算を使った dijk2 の方が dijk1 よりも遅くなりました。ダイクストラのアルゴリズムの場合、キー値の減算を使わなくてもプライオリティキューだけで十分な効果が得られるようです。
●A* アルゴリズムによる探索
始点と終点が決まっていれば、最短経路は A* アルゴリズムで高速に求めることができます。拙作のページ「ヒューリスティック探索」で作成したプログラムを改造すると簡単に作成することができます。次のリストを見てください。
リスト : A* アルゴリズムによる探索
OPEN = 1
CLOSE = 0
# 局面の定義
class State:
def __init__(self, v, p, g, kind = OPEN):
self.v = v # 頂点
self.p = p # 前の局面
# self.d start からの距離
# self.cost コスト
if p is None:
self.d = 0 # start
else:
self.d = p.d + dt[p.v][v]
self.cost = self.d + dis(point_table[v], point_table[g])
self.kind = kind
def __cmp__(x, y):
return x.cost - y.cost
# 経路の生成
def make_path_astar(state):
path = []
while state is not None:
path.append(state.v)
state = state.p
return path
# 探索
def a_star_search(start, goal, size):
q = pqueue.PQueue()
visited = [None] * size
a = State(start, None, goal)
q.push(a)
visited[start] = a
while not q.isEmpty():
a = q.pop()
if a.kind == CLOSE: continue # 廃棄オブジェクトのチェック
for x in adj[a.v]:
b = visited[x]
if b:
# 訪問済みの頂点
l = a.d + dt[a.v][x]
if b.d > l:
# 更新する
if b.kind == OPEN:
b.kind = CLOSE # 廃棄する
b = State(x, a, goal) # 新しいオブジェクト
visited[x] = b # 書き換え
else:
b.p = a
b.d = l
b.cost = b.d + dis(point_table[x], point_table[goal])
b.kind = OPEN
# キューに追加
q.push(b)
else:
# 未訪問の頂点
b = State(x, a, goal)
if x == goal:
return make_path_astar(b)
q.push(b)
visited[x] = b
# a の子ノードは展開済み
a.kind = CLOSE
A* アルゴリズムは、現在地点に到達するまでのコストと、そこからゴールまでに推定されるコストが必要になります。今回の場合、ゴールまでの推定コストを現在地点からゴールまでの直線距離にすると、A* アルゴリズムは正しく動作します。あとは「ヒューリスティック探索」のプログラムとほとんど同じです。
●実行結果 (2)
それでは実行してみましょう。
表 : 実行結果 (単位 ミリ秒)
頂点 = 500
辺 : 距離 : dijk : dijk1 : dijk2 : A*
---------+------+-------+-------+-------+------
3 (1347) : 939 : 22.46 : 3.99 : 5.22 : 2.11
5 (2064) : 920 : 23.44 : 5.29 : 5.80 : 2.52
7 (2681) : 888 : 24.88 : 5.87 : 6.07 : 1.42
頂点 = 1000 辺 : 距離 : dijk : dijk1 : dijk2 : A* ---------+------+-------+-------+-------+------ 3 (2688) : 1004 : 98.00 : 8.25 : 9.75 : 4.95 5 (4101) : 952 : 96.73 : 9.29 : 11.42 : 5.07 7 (5293) : 931 : 93.99 : 11.02 : 12.36 : 3.03
頂点 = 1500 辺 : 距離 : dijk : dijk1 : dijk2 : A* ---------+------+-------+-------+-------+----- 3 (4024) : 978 : 237.9 : 12.07 : 15.27 : 3.97 5 (6143) : 958 : 210.3 : 14.93 : 17.62 : 6.97 7 (7950) : 924 : 213.6 : 16.03 : 17.22 : 3.95
dijk : ダイクストラのアルゴリズム (単純版) dijk1 : ダイクストラのアルゴリズム (改良版1) dijk2 : ダイクストラのアルゴリズム (改良版2) A* : A* アルゴリズム
A* アルゴリズムが一番速くなりました。頂点の個数が増えても A* アルゴリズムならば高速に解くことができます。
なお、これらの結果は M.Hiroi のコーディング、実行したマシン、プログラミング言語などの環境に大きく依存しています。また、これらの環境だけではなく、データの種類によっても実行時間はかなり左右されます。興味のある方は、いろいろなデータをご自分の環境で試してみてください。
●プログラムリスト
#
# edijk.py : ユークリッド距離によるダイクストラ法
#
# Copyright (C) 2012-2022 Makoto Hiroi
#
import sys, math, time, random
import pqueue
import pqueuedk
from tkinter import *
# 無限大
INF = 999999999
# 高さと幅
WIDTH = 900
HEIGHT = 600
# データの生成
def make_data(n, s):
random.seed(s)
buff = []
for _ in range(n):
x = random.randint(0, WIDTH) + 20
y = random.randint(0, HEIGHT) + 20
buff.append((x, y))
return buff
# 距離の計算
def dis(p1, p2):
dx = p1[0] - p2[0]
dy = p1[1] - p2[1]
return int(math.sqrt(dx * dx + dy * dy) + 0.5)
# 隣接行列の作成
def make_adj(n, ps):
size = len(ps)
dt = [[INF] * size for _ in range(size)]
adj = [[] for _ in range(size)]
cnt = 0
for i in range(size):
tmp = [(j, dis(ps[i], ps[j])) for j in range(size)]
tmp.sort(key = lambda y: y[1])
# 短いほうから適当に n 個隣接行列に登録
for j in range(1, n + 1):
k, d = tmp[random.randint(1, 21)]
if dt[i][k] == INF:
dt[i][k] = d
dt[k][i] = d
adj[i].append(k)
adj[k].append(i)
cnt += 1
return dt, adj, cnt
# 経路の長さ
def path_length(path):
n = 0
for i in range(1, len(path)):
n += dis(point_table[path[i-1]], point_table[path[i]])
return n
#
# 頂点とコスト
#
class VCost:
def __init__(self, p, cost):
self.p = p
self.cost = cost # 整数値
def decrease_key(self, x):
self.cost -= x
def __gt__(x, y): return x.cost > y.cost
def __le__(x, y): return x.cost <= y.cost
#
# ダイクストラ法
#
# 経路を作る
def make_path(start, n, prev):
if start == n:
return [start]
else:
return make_path(start, prev[n], prev) + [n]
def dijk(start, goal, size):
cost = [INF] * size
prev = [None] * size
visited = [False] * size
prev[start] = start
cost[start] = 0
s = start
for _ in range(size):
min_cost = INF
next = -1
visited[s] = True
# 頂点の選択
for i in range(size):
if visited[i]: continue
if dt[s][i] < INF:
d = cost[s] + dt[s][i]
if d < cost[i]:
cost[i] = d
prev[i] = s
if min_cost > cost[i]:
min_cost = cost[i]
next = i
s = next
#
return make_path(start, goal, prev)
# PQueue を利用する
def dijk1(start, goal, size):
cost = [INF] * size
prev = [None] * size
visited = [False] * size
cost[start] = 0
#
pq = pqueue.PQueue()
pq.push(VCost(start, cost[start]))
i = 0
while i < size:
v = pq.pop()
if visited[v.p]: continue
visited[v.p] = True
for x in adj[v.p]:
if cost[x] > v.cost + dt[v.p][x]:
cost[x] = v.cost + dt[v.p][x]
prev[x] = v.p
pq.push(VCost(x, cost[x]))
i += 1
#
return make_path(start, goal, prev)
# キー値の減算を利用する
def dijk2(start, goal, size):
cost = [VCost(i, INF) for i in range(size)]
prev = [None] * size
#
cost[start].cost = 0
pq = pqueuedk.PQueue()
pq.push(cost[start])
for _ in range(size):
v = pq.pop()
for x in adj[v.p]:
if cost[x].cost == INF:
cost[x].cost = v.cost + dt[v.p][x]
prev[x] = v.p
pq.push(cost[x])
elif cost[x].cost > v.cost + dt[v.p][x]:
d = cost[x].cost - (v.cost + dt[v.p][x])
prev[x] = v.p
pq.decrease_key(cost[x], d)
#
return make_path(start, goal, prev)
#
# A* アルゴリズムによる探索
#
OPEN = 1
CLOSE = 0
# 局面の定義
class State:
def __init__(self, v, p, g, kind = OPEN):
self.v = v # 頂点
self.p = p # 前の局面
# self.d start からの距離
# self.cost コスト
if p is None:
self.d = 0 # start
else:
self.d = p.d + dt[p.v][v]
self.cost = self.d + dis(point_table[v], point_table[g])
self.kind = kind
def __gt__(x, y): return x.cost > y.cost
def __le__(x, y): return x.cost <= y.cost
# 経路の生成
def make_path_astar(state):
path = []
while state is not None:
path.append(state.v)
state = state.p
return path
# 探索
def a_star_search(start, goal, size):
q = pqueue.PQueue()
visited = [None] * size
a = State(start, None, goal)
q.push(a)
visited[start] = a
while not q.isEmpty():
a = q.pop()
if a.kind == CLOSE: continue # 廃棄オブジェクトのチェック
for x in adj[a.v]:
b = visited[x]
if b:
# 訪問済みの頂点
l = a.d + dt[a.v][x]
if b.d > l:
# 更新する
if b.kind == OPEN:
b.kind = CLOSE # 廃棄する
b = State(x, a, goal) # 新しいオブジェクト
visited[x] = b # 書き換え
else:
b.p = a
b.d = l
b.cost = b.d + dis(point_table[x], point_table[goal])
b.kind = OPEN
# キューに追加
q.push(b)
else:
# 未訪問の頂点
b = State(x, a, goal)
if x == goal:
return make_path_astar(b)
q.push(b)
visited[x] = b
# a の子ノードは展開済み
a.kind = CLOSE
#
# 実行
#
point_size = 500
point_table = make_data(point_size, 1)
point_table.sort(key = lambda x: x[0] * x[0] + x[1] * x[1])
dt, adj, cnt = make_adj(3, point_table)
print('頂点 {:d}, 辺 {:d}'.format(point_size, cnt))
s = time.time()
for _ in range(10): path = dijk(0, point_size - 1, point_size)
print(path_length(path))
print((time.time() - s) / 10)
s = time.time()
for _ in range(10): path = dijk1(0, point_size - 1, point_size)
print(path_length(path))
print((time.time() - s) / 10)
s = time.time()
for _ in range(10): path = dijk2(0, point_size - 1, point_size)
print(path_length(path))
print((time.time() - s) / 10)
s = time.time()
for _ in range(10): path = a_star_search(0, point_size - 1, point_size)
print(path_length(path))
print((time.time() - s) / 10)
#
# 経路の表示
#
def draw_adj(size):
for i in range(size - 1):
for j in range(i + 1, size):
if dt[i][j] < INF:
x0, y0 = point_table[i]
x1, y1 = point_table[j]
id = c0.create_line(x0, y0, x1, y1, fill = "gray")
# path の表示
def draw_path(path):
x0, y0 = path[0]
for i in range(1, len(path)):
x1, y1 = path[i]
c0.create_line(x0, y0, x1, y1, fill = "red", width = 2)
x0, y0 = x1, y1
# 都市の表示
def draw_point():
for x, y in point_table:
c0.create_oval(x - 2, y - 2, x + 2, y + 2, fill = "lightgreen")
root = Tk()
c0 = Canvas(root, width = WIDTH + 40, height = HEIGHT + 40, bg = "white")
c0.pack()
draw_adj(point_size)
draw_path(list(map(lambda x: point_table[x], path)))
draw_point()
root.mainloop()