ラムダ式
最近の規格 (C++11) で導入された機能に「ラムダ式 (lambda expression)」があります。ラムダ式は Lisp / Scheme のラムダ式と同様の機能をC++で実現したものです。簡単に説明すると、ラムダ式は名前の無い関数のことで、関数型言語では「無名関数」とか「匿名関数」と呼ばれることもあります。最近では Java, Perl, Python, Ruby など、多くのプログラミング言語でラムダ式 (無名関数) が導入されています。今回はラムダ式の基本的な使い方を簡単に説明します。
●ラムダ式の構文
C++の STL には便利な高階関数が用意されています。これらの高階関数を使うようになると、たとえば数を 2 乗する square のような小さな関数を定義するのが面倒になります。とくに、その高階関数でしか使わないのであれば、なおさらそう思うでしょう。
このような場合、C++では名前のない関数オブジェクトを生成する「ラムダ式 (lambda expression)」を使うことができます。ラムダはギリシャ文字の λ のことです。ラムダ式の構文を示します。
[ ... ](仮引数, ...) -> 返り値のデータ型 { 本体; ... ; }
[ ... ] は capture 句といって、ラムダ式の中でアクセスする (ラムダ式の外側の) 局所変数を指定します。関数型言語の場合、ラムダ式を実行するときに有効な局所変数は、ラムダ式からアクセスすることができます。C++の場合、[ ... ] の中で局所変数を指定しないと、ラムダ式から外側の局所変数にアクセスすることはできません。これはあとで詳しく説明します。
( ... ) の中は関数定義と同じく仮引数を指定します。引数が無い場合は省略することができます。返り値のデータ型は -> の後ろで指定します。その後ろの { ... } がラムダ式の本体です。返り値が void の場合や、関数本体が return 式; だけの場合は、コンパイラが返り値のデータ型を推論してくれるので、返り値のデータ型を省略することができます。
ラムダ式が生成する無名の関数オブジェクトのデータ型 [*1] は、処理系 (コンパイラ) に依存するためプログラムに記述することはできません。このため、ラムダ式はテンプレート関数の引数に渡したり、auto で宣言した変数に代入して使用します。
または、STL の <functional> に用意されているテンプレートクラス function に格納することもできます。function のテンプレート仮引数には "返り値のデータ型(引数のデータ型, ...)" を渡します。function は関数ラッパーで、関数、関数オブジェクト、ラムダ式、クラスのメンバ関数などを格納して、それを関数と同じ方法で呼び出すことができます。
簡単な使用例を示しましょう。
リスト : ラムダ式の使用例 (sample2601.cpp)
#include <iostream>
#include <functional>
using namespace std;
int main()
{
auto func1 = [](int x, int y){ return x + y; };
function<int(int,int)> func2 = [](int x, int y){ return x * y; };
cout << func1(1, 2) << endl;
cout << func2(10, 20) << endl;
cout << [](int x, int y) { return x - y; }(100, 200) << endl;
}
$ clang++ sample2601.cpp
$ ./a.out
3
200
-100
最初は auto を使って局所変数 func1 にラムダ式が生成する関数オブジェクトをセットします。次は function を使ってラムダ式を変数 func2 にセットします。ラムダ式は int を 2 つ受け取って int を返すので、テンプレート仮引数は int(int, int) になります。
どちらの場合も関数と同じ方法 func1(1, 2) や func2(10, 20) で関数オブジェクトを呼び出すことができます。また、ラムダ式の後ろにカッコを付けて引数を指定すると、ラムダ式をそのまま呼び出すことができます。
ラムダ式を使うと高階関数に関数オブジェクトを簡単に渡すことができます。たとえば、シーケンスの要素を 2 乗する処理は、次のようにラムダ式を使って実現できます。
リスト : ラムダ式と高階関数 (sample2602.cpp)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
template<class T, class F>
T mapcar(F func, const T& seq)
{
T new_seq(seq.size());
auto iter = new_seq.begin();
for (const auto& x: seq) *iter++ = func(x);
return new_seq;
}
int main()
{
vector<int> a = {1,2,3,4,5,6,7,8};
vector<int> b = mapcar([](int x){ return x * x; }, a);
for_each(b.begin(), b.end(), [](int x){ cout << x << " "; });
cout << endl;
}
$ clang++ sample2602.cpp
$ ./a.out
1 4 9 16 25 36 49 64
mapcar は拙作のページ Yet Another C++ Problems (3) で作成したマッピングを行う高階関数です。ラムダ式を使うと square を定義しなくてもいいので簡単です。また、for_each に要素を画面に表示するラムダ式を渡すと、vector のすべての要素を画面に表示することができます。このように、ラムダ式は高階関数と組み合わせて使うととても便利です。
-- note --------
[*1] 関数型言語 (SML/NJ, OCaml, Haskell など) では、関数を表すデータ型が定義されていて、無名関数でもデータ型を記述することができます。たとえば、ML 系の言語では int を受け取って int を返す関数は int -> int と表すことができます。また、型変数を使って 'a -> 'b のように多相型関数のデータ型を記述することもできます。
●レキシカルスコープ
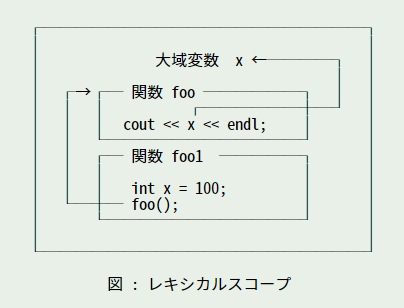
ここで、もう少し詳しく局所変数の規則を見てみましょう。変数 x を表示する関数 foo() を定義します。
リスト : レキシカルスコープ (sample2603.cpp)
#include <iostream>
using namespace std;
int x = 10; // 大域変数
void foo()
{
cout << x << endl;
}
void foo1()
{
int x = 100;
foo();
}
int main()
{
foo();
foo1();
}
$ clang++ sample2603.cpp
$ ./a.out
10
10
foo() には変数 x を定義していないので、foo() を実行した場合は大域変数の値を探しにいきます。それでは foo1() という関数から foo() を呼び出す場合を考えてみましょう。foo1() には局所変数 x を定義します。この場合、foo() はどちらの値を表示するのでしょうか。実際に試してみると、大域変数の値を表示しました。このように、foo1() で定義した局所変数 x は、foo() からアクセスすることはできません。下図を見てください。
上図では、変数の有効範囲を枠で表しています。foo1() で定義した局所変数 x は、関数 foo1() の枠の中でのみ有効です。もしも、この枠で変数が見つからない場合は、ひとつ外側の枠を調べます。この場合、関数定義の枠しかないので、ここで変数が見つからない場合は大域変数を調べます。
foo() は関数定義の枠しかありません。そこに変数 x が定義されていないので、大域変数を調べることになるのです。このように、foo() から foo1() の枠を超えて変数 x にアクセスすることはできないのです。これを「レキシカルスコープ (lexical scope)」といいます。レキシカルには文脈上いう意味があり、変数が定義されている範囲内 (枠内) でないと、その変数にアクセスすることはできません。
●局所変数のキャプチャ
それでは、ラムダ式の場合はどうでしょうか。次のリストを見てください。
リスト : vector の要素を n 倍する (sample2604.cpp)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// mapcar() の定義は省略
vector<int> times_element(vector<int>& v, int n)
{
return mapcar([&](int x){ return x * n; }, v);
}
int main()
{
vector<int> a = {1,2,3,4,5,6,7,8};
vector<int> b = times_element(a, 10);
for_each(b.begin(), b.end(), [](int x){ cout << x << " "; });
cout << endl;
}
$ clang++ sample2604.cpp
$ ./a.out
10 20 30 40 50 60 70 80
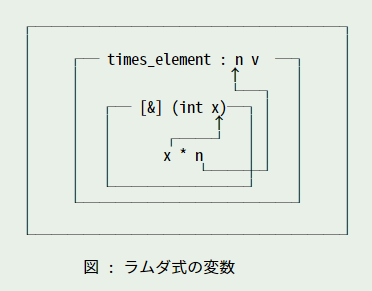
ラムダ式の仮引数は x だけですから、変数 n は大域変数をアクセスすると思われるかもしれません。ところが、ラムダ式の capture 句に & を指定すると、変数 n は関数 times_element の引数 n を参照することができます。下図を見てください。
ポイントは、ラムダ式が関数 times_element() の中で定義されているところです。変数 n は関数の引数として定義されていて、その有効範囲は関数の終わりまでです。ラムダ式はその範囲内に定義されているため、capture 句を指定すれば引数 n にアクセスすることができます。つまり、関数内で定義されたラムダ式は capture 句を指定することで、そのとき有効な局所変数にアクセスすることができるわけです。
capture 句の指定には次の方法があります。
- &
局所変数を参照によりキャプチャ (捕捉) する。関数オブジェクト内にキャプチャした局所変数への参照が保持される。
- =
局所変数をコピーによりキャプチャ (捕捉) する。関数オブジェクト内に局所変数の値がコピーされる。
- &変数名
指定した局所変数を参照によりキャプチャする。
- 変数名
指定した局所変数をコピーによりキャプチャする。
1 と 2 を capture-default といいます。capture-default と 3, 4 の指定方法を組み合わせることもできます。たとえば、局所変数 a, b, c が定義されている場合、[&, c] とすると、a, b が参照でキャプチャされて、c がコピーでキャプチャされます。[=, &c] とすると、a, b がコピーでキャプチャされて、c が参照でキャプチャされます。[=, c] のように、変数 c の指定で capture-default と同じ方法を指定するとエラーになります。
もうひとつ簡単な例題として、vector の中から要素を削除して新しい vector を返す関数 remove と高階関数 remove_if を作ってみましょう。次のリストを見てください。
リスト : vector の要素を削除する (sample2605.cpp)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
template<class T, class F>
vector<T> remove_if(const vector<T>& vec, F func)
{
vector<T> new_vec;
for_each(vec.cbegin(),
vec.cend(),
[&](const T& x){
if (!func(x)) new_vec.push_back(x);
});
return new_vec;
}
template<class T>
vector<T> remove(const vector<T>& vec, const T& x)
{
return remove_if(vec, [&](const T& y){ return x == y; });
}
int main()
{
vector<int> a = {1,2,3,4,5,6,7,8};
vector<int> b = remove_if(a, [](int x) { return x % 2 == 0; });
for_each(b.begin(), b.end(), [](int x) { cout << x << " "; });
cout << endl;
vector<int> c = remove(a, 5);
for_each(c.begin(), c.end(), [](int x) { cout << x << " "; });
cout << endl;
}
$ clang++ sample2605.cpp
$ ./a.out
1 3 5 7
1 2 3 4 6 7 8
remove_if は局所変数 new_vec に空の vector をセットします。次に、for_each で引数の vec の要素を順番に取り出します。このとき、引数のラムダ式が呼び出されます。ラムダ式では capture 句に & を指定しているので、局所変数 new_vec や引数 func にアクセスすることができます。func(x) が false ならば、push_back で new_vec に要素 x を追加します。これで叙述関数 func が真を返す要素を削除することができます。
remove は remove_if を呼び出すと簡単です。ラムダ式の中で引数 x をキャプチャして、x と引数 y が等しい場合は true を返します。これで、x と等しい要素を削除した新しい vector を返すことができます。このように、ラムダ式と高階関数をうまく組み合わせると、ちょっと複雑な処理でも簡単にプログラムを作ることができます。
●クロージャ
次は「クロージャ (closure)」について説明します。クロージャは評価する関数と参照可能な局所変数をまとめたものです。クロージャは関数のように実行することができますが、クロージャを生成するときに参照可能な局所変数を保存するところが異なります。参照可能な局所変数の集合を「環境」と呼ぶことがあります。
C++でクロージャを生成するには「ラムダ式」を使います。クロージャを使うと、関数を生成する関数を簡単に定義することができます。たとえば、「引数を n 倍する関数」を生成する関数は、ラムダ式を使うと次のようになります。
リスト : クロージャの生成 (sample2606.cpp)
#include <iostream>
#include <functional>
using namespace std;
function<int(int)> foo(int n)
{
return [=](int x){ return n * x; };
}
int main()
{
auto foo10 = foo(10);
cout << foo10(1) << endl;
cout << foo10(10) << endl;
auto foo5 = foo(5);
cout << foo5(11) << endl;
cout << foo5(111) << endl;
}
$ clang++ sample2606.cpp
$ ./a.out
10
100
55
555
関数 foo は引数を n 倍する関数オブジェクトを生成します。ラムダ式を返す場合、返り値のデータ型は function< ... > で指定します。変数 foo10 に foo(10) の返り値をセットします。すると、foo10 は引数を 10 倍する関数として使うことができます。同様に、変数 foo5 に foo(5) の返り値をセットすると、foo5 は引数を 5 倍する関数になります。
ラムダ式を返すとき、局所変数はコピーでキャプチャすることに注意してください。ラムダ式の中で必要な関数 foo の局所変数は引数 n です。関数の局所変数 (引数) は関数の実行が終了するとき廃棄されます。参照でキャプチャすると、廃棄されたメモリ領域を参照することになるので、プログラムは正常に動作しません。ご注意くださいませ。
foo(10) を実行して関数オブジェクトを生成するとき、キャプチャされる変数は n で、その値は 10 です。この値が関数オブジェクトに保存されるので、foo10 の関数は引数を 10 倍した結果を返します。foo(5) を評価すると n の値は 5 で、それが関数オブジェクトに保存されるので、foo5 の関数は引数を 5 倍した結果を返すのです。
●ジェネレータ
もう一つ簡単な例題として、フィボナッチ数列を生成するジェネレータをラムダ式で作ってみましょう。ラムダ式を使うとジェネレータも簡単に定義することができます。
この場合、関数オブジェクトにコピーでキャプチャされている変数の値を書き換える必要があります。参考文献 1 によると、ラムダ式で生成される関数オブジェクトの呼び出しは const で修飾されているため、キャプチャした変数の値を書き換えることができません。変数の値を書き換えるには、引数を指定するカッコの後ろに mutable を指定します。
[=]( ... ) mutable -> 返り値の型 { 本体; }
これでコピーキャプチャした変数の値を書き換えることができます。プログラムは次のようになります。
リスト : フィボナッチ数列を生成するジェネレータ (sample2607.cpp)
#include <iostream>
#include <functional>
using namespace std;
function<int(void)> make_fibo()
{
int a = 0, b = 1;
return [=]() mutable -> int {
int c = a;
a += b;
b = c;
return c;
};
}
int main()
{
auto fibo = make_fibo();
for (int i = 0; i < 20; i++)
cout << fibo() << " ";
cout << endl;
}
$ clang++ sample2607.cpp
$ ./a.out
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
コピーキャプチャされる局所変数は a, b です。mutable の指定すると、a += b; とか b = c; のように、キャプチャした変数の値を書き換えることができます。make_fibo() が生成したジェネレータを呼び出すと、フィボナッチ数列を順番に生成していきます。
クロージャは少し難しいかもしれませんが、便利で面白い機能です。少々歯応えがありますが、 これもプログラミングの面白いところだと思います。興味のある方はいろいろと試してみてください。 また、関数を扱うことは、やっぱり関数型言語の方が優れています。クロージャの話に興味をもたれた方は、ぜひ関数型言語 (Lisp, ML, Haskell など) にも挑戦してみてください。
●参考 URL
- 本の虫: lambda 完全解説, (江添亮さん)
- C++ でのラムダ式, (Microsoft Developer Network)
初版 2015 年 10 月 24 日
改訂 2023 年 4 月 15 日
ベクタクラスの作成 (テンプレート編)
今回は簡単な例題として、以前作成したベクタクラス IntVec をテンプレートを使って書き直してみましょう。名前は Vector とします。なお、C++の標準ライブラリには <vector> や <array> が用意されているので、私たちが Vector クラスを作成する必要はありませんが、テンプレートのお勉強ということで、あえてプログラムを作ってみましょう。
●Vector クラスの定義
さっそくプログラムを作りましょう。Vector の定義は次のようになります。
リスト : クラス Vector の定義
// 宣言
template<class T> class Vector;
template<class T> ostream& operator<<(ostream&, const Vector<T>&);
// ベクタクラス
template<class T> class Vector {
T* buff;
size_t buff_size;
public:
explicit Vector(size_t n) : buff(new T [n]), buff_size(n) { }
~Vector() { delete[] buff; }
Vector(const Vector&); // コピーコンストラクタ
Vector& operator=(const Vector&); // 代入演算子
Vector(Vector&&); // ムーブコンストラクタ
Vector& operator=(Vector&&); // ムーブ代入演算子
T& operator[](int); // 添字演算子
// 出力演算子 << の後ろに <T> が必要
friend std::ostream& operator<< <T> (std::ostream&, const Vector&);
// その他のメンバ関数
size_t size() const { return buff_size; }
//
// ・・・イテレータは省略・・・
//
};
Vector で出力演算子を多重定義する場合、関数テンプレートで定義することになります。関数がテンプレートで、それをクラスで friend 宣言する場合、参考 URL (Sun Studio 12: C++ ユーザーズガイド 6.7.3 テンプレート関数のフレンド宣言) によると、あらかじめその関数がテンプレートであることを宣言する必要があるそうです。詳細は参考 URL をお読みください。
宣言の方法は簡単で、プロトタイプの前に template<class T, ...> を付けるだけです。たとえば、template<class T> Vector; とすれば、Vector はテンプレートであることが宣言されます。関数を宣言するときも同じです。 operator<< の前に template <class T> を付けます。引数のデータ型 Vector はテンプレートなので、後ろに <T> を付けます。それから、Vector 内の friend 宣言では、operator<< の後ろに <T> を付けてください。
operator << の定義は次のようになります。
リスト : 出力演算子の多重定義
template<class T>
ostream& operator<<(ostream& output, const Vector<T>& v)
{
output << "[";
int i = 0;
for (; i < v.size - 1; i++)
output << v.buff[i] << ",";
output << v.buff[i] << "]";
return output;
}
テンプレート仮引数 T を使ってデータ型を記述します。Vector の外側で定義するので、クラス Vector のデータ型は Vector<T> になります。<T> を付け忘れないように注意してください。
●メンバ関数の定義
次はメンバ関数を作ります。
リスト : メンバ関数
// コピーコンストラクタ
template<class T>
Vector<T>::Vector(const Vector<T>& v) : buff(new T [v.size]), size(v.size)
{
for (int i = 0; i < size; i++) buff[i] = v.buff[i];
}
// 代入演算子
template<class T>
Vector<T>& Vector<T>::operator=(const Vector<T>& v)
{
if (this != &v) {
if (size != v.size) {
delete[] buff;
size = v.size;
buff = new T [size];
}
for (int i = 0; i < size; i++) buff[i] = v.buff[i];
}
return *this;
}
// ムーブコンストラクタ
template<class T>
Vector<T>::Vector(Vector&& v)
: buff(v.buff), buff_size(v.buff_size)
{
v.buff = nullptr;
v.buff_size = 0;
}
// ムーブ代入演算子
template<class T>
Vector<T>& Vector<T>::operator=(Vector&& v)
{
if (this != &v) {
delete[] buff;
buff = v.buff;
buff_size = v.buff_size;
v.buff = nullptr;
v.buff_size = 0;
}
return *this;
}
// 配列添字演算子
template <class T>
T& Vector<T>::operator[](int i)
{
if (i < 0 || i >= size) throw out_of_range("Vector: out of range");
return buff[i];
}
関数定義の先頭に template<class T> を付けて、スコープ解決演算子でクラス名を指定します。このとき、クラス名は Vector<T> になります。あとはとくに難しいところはないでしょう。
●イテレータの定義
次はイテレータを作ります。自作のコンテナクラスにイテレータを定義する場合、STL の <iterator> に用意されているテンプレートクラス iterator を public で継承します。iterator には複数のテンプレート仮引数がありますが、最初の 2 つ (イテレータの種類、データ型) を必ず指定してください。あとの仮引数はデフォルト値が設定されているので、通常はそのままで大丈夫です。
イテレータの種類は次のデータで指定します。
- input_iterator_tag : 入力イテレータ
- output_iterator_tag : 出力イテレータ
- forward_iterator_tag : 前方向イテレータ
- bidirectional_iterator_tag : 双方向イテレータ
- random_access_iterator_tag : ランダムイテレータ
Vector はランダムアクセスができるので、ランダムイテレータを実装します。イテレータは内部クラスで定義すると簡単です。次のリストを見てください。
リスト : イテレータ
class Iterator : public iterator<random_access_iterator_tag, T> {
Vector* vec;
int idx;
public:
// コンストラクタ
Iterator(Vector* v, int n) : vec(v), idx(n) { }
// 間接参照 *, ->
// ++, -- 演算子 (前置、後置)
// +=, -=, +, - 演算子
// 比較演算子 ==, !=, < <=, > >=
};
Iterator begin() { return Iterator(this, 0); }
Iterator end() { return Iterator(this, buff_size); }
多重定義する演算子の仕様を下表に示します。
表 : イテレータで多重定義する演算子
| 演算子 | 機能 |
|---|
| T& operator*() | 間接参照演算子 |
| T* operator->() | 要素がクラス (構造体) の場合、メンバを選択する |
| Iterator& operator++() | 前置の ++ 演算子 |
| Iterator operator++(int n) | 後置の ++ 演算子はイテレータのコピーを返す (引数はダミー) |
| Iterator& operator--() | 前置の -- 演算子 |
| Iterator operator--(int n) | 後置の -- 演算子はイテレータのコピーを返す (引数はダミー) |
| Iterator& operator+=(size_t n) | イテレータを n 個進める |
| Iterator& operator-=(size_t n) | イテレータを n 個戻す |
| Iterator operator+(size_t n) | n 個進めた新しいイテレータを返す |
| Iterator operator-(size_t n) | n 個戻した新しいイテレータを返す |
| bool operator==(const Iterator& iter) const | iter と等しいとき真を返す |
| bool operator!=(const Iterator& iter) const | iter と等しくないとき真を返す |
| bool operator<(const Iterator& iter) const | iter よりも小さいとき真を返す |
| bool operator<=(const Iterator& iter) const | iter 以下のときに真を返す |
| bool operator>(const Iterator& iter) const | iter よりも大きいとき真を返す |
| bool operator>=(const Iterator& iter) const | iter 以上のとき真を返す |
プログラムは簡単なので説明は割愛します。詳細は プログラムリスト をお読みください。
●簡単なテスト
それは実際に実行してみましょう。次に示す簡単なテストを行ってみました。
リスト : 簡単なテスト
int main()
{
Vector<int> a(8);
for (int i = 0; i < a.size(); i++) a[i] = i;
Vector<int> b = a;
for (int i = 0; i < b.size(); i++) b[i] *= 2;
cout << a << endl;
cout << b << endl;
{
Vector<int> c = a;
a = b;
b = c;
}
cout << a << endl;
cout << b << endl;
{
Vector<int> c = move(a);
a = move(b);
b = move(c);
}
cout << a << endl;
cout << b << endl;
for (auto iter = a.begin(); iter < a.end(); iter += 2)
cout << *iter << " ";
cout << endl;
auto iter = b.begin();
while (iter != b.end())
cout << *iter++ << " ";
cout << endl;
for (auto x : a) cout << x << " ";
cout << endl;
for_each(a.begin(), a.end(), [](int x){ cout << x << " "; });
cout << endl;
Vector<pair<string,int>> c(4);
c[0].first = "foo";
c[0].second = 1;
c[1].first = "bar";
c[1].second = 2;
c[2].first = "baz";
c[2].second = 3;
c[3].first = "oops";
c[3].second = 4;
for (auto iter = c.begin(); iter != c.end(); iter++)
cout << iter->first << "," << iter->second << endl;
}
$ clang++ vector.cpp
$ ./a.out
[0,1,2,3,4,5,6,7]
[0,2,4,6,8,10,12,14]
[0,2,4,6,8,10,12,14]
[0,1,2,3,4,5,6,7]
[0,1,2,3,4,5,6,7]
[0,2,4,6,8,10,12,14]
0 2 4 6
0 2 4 6 8 10 12 14
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
foo,1
bar,2
baz,3
oops,4
コピーコンストラクタ、代入演算子、ムーブコンストラクタ、ムーブ代入演算子は正常に動作しています。添字演算子も大丈夫ですね。STL の仕様に合わせてイテレータを実装すると、範囲 for 文や、for_each() など algorithm の関数も利用することができます。
Vector に pair<string, int> を格納することもできます。このとき、pair のデフォルトコンストラクタによりベクタが初期化されます。ベクタを廃棄するときは、pair のデストラクタが実行されます。-> で pair のメンバ変数 first, second を選択することができます。興味のある方はいろいろ試してみてください。
●プログラムリスト
//
// vector.cpp : ベクタクラス (テンプレート版)
//
// Copyright (C) 2015-2023 Makoto Hiroi
//
#include <iostream>
#include <stdexcept>
#include <iterator>
#include <algorithm>
using namespace std;
// 宣言
template<class T> class Vector;
template<class T> ostream& operator<<(ostream&, const Vector<T>&);
// ベクタクラス
template<class T> class Vector {
T* buff;
size_t buff_size;
public:
explicit Vector(size_t n) : buff(new T [n]), buff_size(n) { }
~Vector() { delete[] buff; }
Vector(const Vector&); // コピーコンストラクタ
Vector& operator=(const Vector&); // 代入演算子
Vector(Vector&&); // ムーブコンストラクタ
Vector& operator=(Vector&&); // ムーブ代入演算子
T& operator[](int); // 添字演算子
// 出力演算子 << の後ろに <T> が必要
friend std::ostream& operator<< <T> (std::ostream&, const Vector&);
// その他のメンバ関数
size_t size() const { return buff_size; }
// イテレータ
class Iterator : public iterator<random_access_iterator_tag, T> {
Vector* vec;
int idx;
public:
// コンストラクタ
Iterator(Vector* v, int n) : vec(v), idx(n) { }
// 間接参照
T& operator*() { return vec->buff[idx]; }
T* operator->() { return &vec->buff[idx]; }
// 前置の ++, -- 演算子
Iterator& operator++() {
idx++;
return *this;
}
Iterator& operator--() {
idx--;
return *this;
}
// 後置の ++, -- 演算子, 引数はダミー
Iterator operator++(int n) {
Iterator iter(*this);
idx++;
return iter;
}
Iterator operator--(int n) {
Iterator iter(*this);
idx--;
return iter;
}
// +=, -=
Iterator& operator+=(size_t n) {
idx += n;
return *this;
}
Iterator& operator-=(size_t n) {
idx -= n;
return *this;
}
// +, -
Iterator operator+(size_t n) {
return Iterator(vec, idx + n);
}
Iterator operator-(size_t n) {
return Iterator(vec, idx - n);
}
// 比較演算子
bool operator==(const Iterator& iter) const {
return vec == iter.vec && idx == iter.idx;
}
bool operator!=(const Iterator& iter) const {
return vec != iter.vec || idx != iter.idx;
}
bool operator<(const Iterator& iter) const {
return vec == iter.vec && idx < iter.idx;
}
bool operator<=(const Iterator& iter) const {
return vec == iter.vec && idx <= iter.idx;
}
bool operator>(const Iterator& iter) const {
return vec == iter.vec && idx > iter.idx;
}
bool operator>=(const Iterator& iter) const {
return vec == iter.vec && idx >= iter.idx;
}
};
Iterator begin() { return Iterator(this, 0); }
Iterator end() { return Iterator(this, buff_size); }
};
// コピーコンストラクタ
template<class T>
Vector<T>::Vector(const Vector& v)
: buff(new T [v.buff_size]), buff_size(v.buff_size)
{
for (int i = 0; i < buff_size; i++) buff[i] = v.buff[i];
}
// 代入演算子
template<class T>
Vector<T>& Vector<T>::operator=(const Vector<T>& v)
{
if (this != &v) {
delete[] buff;
buff_size = v.buff_size;
buff = new T [buff_size];
for (int i = 0; i < buff_size; i++) buff[i] = v.buff[i];
}
return *this;
}
// ムーブコンストラクタ
template<class T>
Vector<T>::Vector(Vector&& v)
: buff(v.buff), buff_size(v.buff_size)
{
v.buff = nullptr;
v.buff_size = 0;
}
// ムーブ代入演算子
template<class T>
Vector<T>& Vector<T>::operator=(Vector&& v)
{
if (this != &v) {
delete[] buff;
buff = v.buff;
buff_size = v.buff_size;
v.buff = nullptr;
v.buff_size = 0;
}
return *this;
}
// 添字
template <class T>
T& Vector<T>::operator[](int i)
{
if (i < 0 || i >= buff_size)
throw std::out_of_range("Vector: out of range");
return buff[i];
}
// 出力
template<class T>
std::ostream& operator<<(std::ostream& output, const Vector<T>& v)
{
output << "[";
int i = 0;
for (; i < v.buff_size - 1; i++)
output << v.buff[i] << ",";
output << v.buff[i] << "]";
return output;
}
// 簡単なテスト
int main()
{
Vector<int> a(8);
for (int i = 0; i < a.size(); i++) a[i] = i;
Vector<int> b = a;
for (int i = 0; i < b.size(); i++) b[i] *= 2;
cout << a << endl;
cout << b << endl;
{
Vector<int> c = a;
a = b;
b = c;
}
cout << a << endl;
cout << b << endl;
{
Vector<int> c = move(a);
a = move(b);
b = move(c);
}
cout << a << endl;
cout << b << endl;
for (auto iter = a.begin(); iter < a.end(); iter += 2)
cout << *iter << " ";
cout << endl;
auto iter = b.begin();
while (iter != b.end())
cout << *iter++ << " ";
cout << endl;
for (auto x : a) cout << x << " ";
cout << endl;
for_each(a.begin(), a.end(), [](int x){ cout << x << " "; });
cout << endl;
Vector<pair<string,int>> c(4);
c[0].first = "foo";
c[0].second = 1;
c[1].first = "bar";
c[1].second = 2;
c[2].first = "baz";
c[2].second = 3;
c[3].first = "oops";
c[3].second = 4;
for (auto iter = c.begin(); iter != c.end(); iter++)
cout << iter->first << "," << iter->second << endl;
}
初版 2015 年 10 月 24 日
改訂 2023 年 4 月 15 日