6月18日
●JuMP.jl
JuMP.jl は Julia で数理最適化を行うときの業界標準パッケージ (ライブラリ) です。JuMP.jl を使うと、Julia で変数や数式を記述することができます。今回は JuMP.jl と HiGHS を使って、PuLP による数理最適化超入門 の最初の例題を解いてみましょう。
●インストール
Julia のパッケージモード (REPL で ] キーを押す) で次のコマンドを実行します。
(@v1.12) pkg> add JuMP HiGHS
JuMP と HiGHS をインストールします。インストール終了後 st で状態を表示すると、M.Hiroi の環境では次のように表示されます。
(@v1.12) pkg> st
Status `~/.julia/environments/v1.12/Project.toml`
[336ed68f] CSV v0.10.16
[a93c6f00] DataFrames v1.8.2
[31c24e10] Distributions v0.25.126
[87dc4568] HiGHS v1.23.0
[4076af6c] JuMP v1.30.1
[91a5bcdd] Plots v1.41.6
[2913bbd2] StatsBase v0.34.11
[f3b207a7] StatsPlots v0.15.8
[bd369af6] Tables v1.12.1
インストールが終了したら、Backspace または Ctrl + C を押してください。通常の julia> プロンプトに戻ります。
●プログラム
PuLP のプログラム (test1.py) を JuMP で書き直すと、次のようになります。右側のコメントに PuLP (Python) のプログラムを残してあります。
リスト : 線形計画法 (test1.jl)
# PuLP (Python)
using JuMP, HiGHS # import pulp
# モデルの生成
model = Model(HiGHS.Optimizer) # prob = pulp.LpProblem('sample')
# 変数の定義 (下限を 0 に設定)
@variable(model, x >= 0) # x = pulp.LpVariable('x', lowBound = 0)
@variable(model, y >= 0) # y = pulp.LpVariable('y', lowBound = 0)
# 目的関数
@objective(model, Min, x + y + 1) # prob += x + y + 1
# 制約条件
@constraint(model, 3x + 5y <= 15) # prob += 3 * x + 5 * y <= 15
@constraint(model, 2x + y >= 4) # prob += 2 * x + y >= 4
@constraint(model, x - y == 1) # prob += x - y == 1
# print(prob)
# 実行
optimize!(model) # status = prob.solve(pulp.PULP_CBC_CMD(msg=0))
# print("Status", pulp.LpStatus[status])
# 結果の確認
println("最適化ステータス: ", termination_status(model)) # OPTIMAL(最適)と出れば成功
println("目的関数の最大値: ", objective_value(model))
println("最適解 x = ", value(x))
println("最適解 y = ", value(y))
# print("Result")
# print("x", x.value())
# print("y", y.value())
# print("z", prob.objective.value())
PuLP と JuMP のプログラムは同じような構造をしています。JuMP の場合、最初に関数 Model() でモデルを生成します。次に、マクロ @variable() で変数を定義し、マクロ @objective() で目的関数を定義します。そして、マクロ @constraint() で制約条件を設定します。関数 optimize!() を実行すると、HiGHS を呼び出して最適解を求めます。最後に結果を表示します。PuLP を使ったことがあれば、JuMP のプログラムを理解するのは難しくはないでしょう。
●実行結果
それでは実行してみましょう。
$ julia test1.jl
Running HiGHS 1.14.0 (git hash: 7df0786de3): Copyright (c) 2026 under Apache 2.0 license terms
Using BLAS: blastrampoline
LP has 3 rows; 2 cols; 6 nonzeros
Coefficient ranges:
Matrix [1e+00, 5e+00]
Cost [1e+00, 1e+00]
Bound [0e+00, 0e+00]
RHS [1e+00, 2e+01]
Presolving model
0 rows, 0 cols, 0 nonzeros 0s
0 rows, 0 cols, 0 nonzeros 0s
Presolve reductions: rows 0(-3); columns 0(-2); nonzeros 0(-6) - Reduced to empty
Performed postsolve
Solving the original LP from the solution after postsolve
Model status : Optimal
Objective value : 3.3333333333e+00
P-D objective error : 1.1584935909e-16
HiGHS run time : 0.01
最適化ステータス: OPTIMAL
目的関数の最大値: 3.333333333333334
最適解 x = 1.6666666666666667
最適解 y = 0.6666666666666667
このように数式を入力するだけで、簡単に解を求めることができました。興味のある方はいろいろ試してみてください。
6月16日
●HiGHS
HiGHS (ハイズ) は、オープンソースの数理最適化ソルバーです。エディンバラ大学を中心に開発され、商用利用が可能な MITライセンス で提供されています。数理最適化はソルバーが商用非商用とわず開発されていて、それを使って解くのが一般的です。もちろん商用のソルバーのほうが高性能なのですが、近年ソルバーの性能は著しく向上していて、非商用 (無料) のソルバーでもかなりの問題を解くことができるようです。その中で HiGHS は従来のオープンソースソルバー (CBC や GLPK など) を大きく上回る性能を持つと言われていて、現在は世界中で標準的なツールとして採用されています。
ソルバーは数理モデル (変数、制約条件、目的関数など) を入力とし、それを解いた結果 (最適値) を出力します。数理モデルの記述には標準的なフォーマットがあるようですが、それらを自分で書くのは大変なので、モデリング言語を使うのが一般的です。たとえば、Python であればライブラリ PuLP を使うと、Python で変数や数式を記述することができます。HiGHS をインストールすれば、PuLP から HiGHS を呼び出すことができます。また、Julia であればライブラリ JuMP.jl を使うと同様なことが可能です。
PuLP については、拙作のページ PuLP による数理最適化超入門 をお読みくださいませ。Python の場合、HiGHS は次のコマンドで簡単にインストールすることができます。
(.venv) $ pip install highspy
(.venv) $ pip freeze | grep highspy
highspy==1.14.0
M.Hiroi の環境では version 1.14.0 がインストールされました。
それでは PuLP による数理最適化超入門 の最初の例題を HiGHS を使って解いてみましょう。プログラムの修正は簡単です。次のリストを見てください。
リスト : 線形計画法 (test1.py)
import pulp
prob = pulp.LpProblem('sample')
# 変数の定義
x = pulp.LpVariable('x', lowBound = 0)
y = pulp.LpVariable('y', lowBound = 0)
# 目的関数
prob += x + y + 1
# 制約条件
prob += 3 * x + 5 * y <= 15
prob += 2 * x + y >= 4
prob += x - y == 1
print(prob)
# 実行
status = prob.solve(pulp.HiGHS(msg=True)) # PULP_CBC_CMD を HiGHS に書き換えるだけ
print("Status", pulp.LpStatus[status])
# 結果の表示
print("Result")
print("x", x.value())
print("y", y.value())
print("z", prob.objective.value())
pulp.PULP_CBC_CMD() を pulp.HiGHS() に書き換えます。これで HiGHS を呼び出すことができます。実行結果は次のようになります。
(.venv) $ python3 test1.py
sample:
MINIMIZE
1*x + 1*y + 1
SUBJECT TO
_C1: 3 x + 5 y <= 15
_C2: 2 x + y >= 4
_C3: x - y = 1
VARIABLES
x Continuous
y Continuous
Running HiGHS 1.14.0 (git hash: 7df0786): Copyright (c) 2026 under MIT licence terms
LP has 3 rows; 2 cols; 6 nonzeros
Coefficient ranges:
Matrix [1e+00, 5e+00]
Cost [1e+00, 1e+00]
Bound [0e+00, 0e+00]
RHS [1e+00, 2e+01]
Presolving model
0 rows, 0 cols, 0 nonzeros 0s
0 rows, 0 cols, 0 nonzeros 0s
Presolve reductions: rows 0(-3); columns 0(-2); nonzeros 0(-6) - Reduced to empty
Performed postsolve
Solving the original LP from the solution after postsolve
Model status : Optimal
Objective value : 2.3333333333e+00
P-D objective error : 7.8368684091e-17
HiGHS run time : 0.01
Status Optimal
Result
x 1.6666666666666667
y 0.6666666666666665
z 3.3333333333333335
メッセージを見ると、HiGHS が呼び出されていることがわかります。ご参考までに、PuLP による数理最適化超入門 : 巡回セールスマン問題 のプログラム (tsp.py) の実行時間を示します。
表 : 実行結果 (秒)
都市 : 距離 : CBC : HiGHS
------+--------+-------+-------
30 : 2107.1 : 2.92 : 4.79
31 : 2110.0 : 1.01 : 3.06
32 : 2000.5 : 0.32 : 0.31
33 : 2407.4 : 34.29 : 13.60
34 : 2318.3 : 1.89 : 3.05
35 : 2332.2 : 3.12 : 6.80
------+--------+-------+-------
(計) : 43.55 : 31.61
- 実行環境 : Python 3.12.3, PuLP 3.3.0, Ubunts 24.04 LTS (WSL2, Windows 11), intel CORE i5-1235U 1.30GHz
都市数 33 の場合、CBC では極端に遅くなりますが、HiGHS では 2.5 倍の速さで解くことができました。それ以外の場合、CBC の方が高速ですね。HiGHS に適した制約条件があるのかもしれません。興味のある方はいろいろ試してみてください。
2月18日
●CustomTkinter
CustomTkinterは、Python の標準 GUI ライブラリである Tkinter をベースに、モダンなデザインのウィジェットや機能を追加した拡張ライブラリです。主な開発者は Tom Schimansky 氏で、2021 年頃にこのプロジェクトを公開し、現在も中心となってメンテナンスを行っています。MIT ライセンスの下で提供されており、個人・商用問わず広く利用可能です。
CustomTkinter は標準の Tkinter と書き方がほぼ同じため、Tkinter ユーザーには学習しやすいツールだと思います。学習曲線が緩やかなのにもかかわらず、「見た目が古臭い」という Tkinter の問題点を解決し、洗練された GUI アプリケーションを開発できることから、人気急上昇中のライブラリです。
CustomTkinter は pip を使って簡単にインストールすることができます。pip は仮想環境下で実行してください。
(.venv) $ pip install customtkinter
M.Hiroi の環境では、customtkinter 5.2.2 がインストールされました (2026 年 2 月時点)。
それでは実際にプログラムを作ってみましょう。ボタンをひとつ表示します。
リスト : ボタンの表示
import customtkinter as ctk
root = ctk.CTk()
button = ctk.CTkButton(root, text = 'Hello, Tkinter', font = ('Noto Sans CJK JP', 20))
button.pack(padx=5, pady=5)
root.mainloop()
最初に customtkinter をインポートして ctk という別名を付けます。次に、CTk() でメインウィンドウを作成します。CTk() は Tkinter の Tk() に相当します。CTk() はクラス CTk のインスタンス (オブジェクト) を生成して返します。このオブジェクトが画面上のメインウィンドウに対応します。
次にボタンを作ります。Tkinter の場合、コンストラクタ Button() でボタンのオブジェクトを生成します。CostumTkinter の場合、Tkinter のコンストラクタの前に CTk を付けたものがコンストラクタになります。ボタンの場合は CTkButton() となります。引数は Tkinter に準じますが、異なるところもあります。
たとえば、フォントのサイズですが、Tkinter ではサイズが正の整数であればポイント単位 (p) に、負の整数であればピクセル単位 (px) になります。CoustomTkinter の場合、サイズはピクセル単位になることに注意してください。
この段階では、ボタンはまだ配置されていません。ボタンの配置はメソッド pack() で行います。Tk (CustomTkinter を含む) の場合、ウィジェットの配置はジオメトリマネージャが行います。3 種類のマネージャがあって、pack() はそのうちのひとつです。button.pack() が実行されると、ウィンドウにボタンが配置されます。最後にメソッド mainloop() を呼び出して、イベントループを開始します。このように、CustomTkinter のプログラムは Tkinter とほとんど同じであることがわかります。
実行結果を示します。
 CustomTkinter のボタン
CustomTkinter のボタン
Tkinter と違って、おしゃれなボタンですね。興味のある方はいろいろ試してみてください。
1月30日
●プログラミング言語のインストール
今回は SBCL (Common Lisp) と Ruby をインストールして、たらいまわし関数で実行速度を計測しました。Linux 系 OS で SBCL をインストールする場合、パッケージ管理ツールを使ったほうが簡単でしょう。Ubuntu であれば、次のコマンドで SBCL をインストールすることができます。
sudo apt install sbcl
Ubuntu 24.04 (WSL2, Windows11) の場合、SBCL 2.2.9 がインストールされます。
たらいまわし関数とその実行結果を以下に示します。
リスト : たらいまわし関数 (Common Lisp)
(defun tak (x y z)
(if (<= x y)
z
(tak (tak (1- x) y z)
(tak (1- y) z x)
(tak (1- z) x y))))
* (time (tak 22 11 0))
Evaluation took:
3.026 seconds of real time
2.863591 seconds of total run time (2.862462 user, 0.001129 system)
94.65% CPU
7,147,539,961 processor cycles
0 bytes consed
11
* (time (tak 24 12 0))
Evaluation took:
19.459 seconds of real time
18.400291 seconds of total run time (18.400285 user, 0.000006 system)
94.56% CPU
45,927,272,428 processor cycles
0 bytes consed
1
以前のパソコン (Ubuntu 22.04, WSL2, Windows10, Intel Core i5-6200U 2.30GHz) の場合、(tak 22 11 0) は 4.90 秒かかりましたが、今のパソコンでは 3.03 秒ですみました。ところで、Common Lisp の場合、次のように関数単位でデータ型や最適化の指定を行うことができます。
リスト : たらいまわし関数 (Common Lisp, 最適化の指定)
(defun tak (x y z)
(declare (type fixnum x y z)
(optimize (speed 3) (safety 0)))
(if (<= x y)
z
(tak (tak (1- x) y z)
(tak (1- y) z x)
(tak (1- z) x y))))
* (time (tak 22 11 0))
Evaluation took:
0.882 seconds of real time
0.835476 seconds of total run time (0.835476 user, 0.000000 system)
94.67% CPU
2,085,342,053 processor cycles
0 bytes consed
11
* (time (tak 24 12 0))
Evaluation took:
5.727 seconds of real time
5.415333 seconds of total run time (5.415333 user, 0.000000 system)
94.55% CPU
13,516,779,071 processor cycles
0 bytes consed
1
最適化を指定すると、SBCL はC言語にせまる速度を叩き出します。あらためて SBCL の性能はすごいなと感心しました。
Ruby の場合、apt を使ってもいいのですが、少々古いバージョンがインストールされるようです。そこで、今回は snap というツールを使ってみることにしましょう。snap は canonical が開発している新しいパッケージシステムで、Ubuntu 16.04 以降のディストリビューションなら以下のコマンドで ruby をインストールすることができます。
sudo snap install ruby --classic
これで最新 の Ruby (安定板) をインストールすることができます。
$ ruby --version
ruby 4.0.0 (2025-12-25 revision 553f1675f3) +PRISM [x86_64-linux]
たらいまわし関数と実行結果を以下に示します。
リスト : たらいまわし関数 (tarai.rb)
def tak(x, y, z)
return z if x <= y
tak(tak(x - 1, y, z), tak(y - 1, z, x), tak(z - 1, x, y))
end
$ irb
irb(main):001> require "benchmark"
=> true
irb(main):002> load "tarai.rb"
=> true
irb(main):003> Benchmark.realtime { tak(22, 11, 0) }
=> 13.76934446999985
前のパソコンの Ruby (ver 3.0.2p107) では 25.59 秒かかりましたが、今のパソコンでは 13.77 秒ですみました。最新の PC ではありませんが、プログラミングを楽しむには十分すぎる性能だと思いました。
1月26日
●新しいパソコン
今まで使っていたパソコン (Windows 10) が壊れたので、新しいノート PC (Windows 11) を買いました。CPU は intel CORE i5-1235U 1.3 GHz、メモリは 8 G byte です。最新のノート PC ではないので、高スペックではありませんが、起動やシャットダウンが今までの PC よりも格段に速くなったのには驚きました。
どのくらい速くなったのか、いつもの「たらいまわし関数」で調べてみました。使用する言語はC言語 (gcc) です。
リスト : たらいまわし関数
#include <stdio.h>
int tak(int x, int y, int z)
{
if (x <= y) {
return z;
} else {
return tak(tak(x - 1, y, z), tak(y - 1, z, x), tak(z - 1, x, y));
}
}
int main(void)
{
printf("%d\n", tak(24, 12, 0));
return 0;
}
$ gcc --version
gcc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
$ gcc -O2 -o takg tak.c
$ time ./takg
1
real 0m7.695s
user 0m7.694s
sys 0m0.000s
- 実行環境 : Ubunts 22.04 LTS (WSL2, Windows 10), Intel Core i5-6200U 2.30GHz
$ gcc --version
gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0
$ gcc -O2 -o takg tak.c
$ time ./takg
1
real 0m3.851s
user 0m3.786s
sys 0m0.001s
- 実行環境 : Ubunts 24.04 LTS (WSL2, Windows 11), Intel Core i5-1235U 1.3 GHz
tak(24, 12, 0) で約 2 倍ほど速くなっています。最近の PC は低価格でも高性能ですね。ちなみに、Python3 で tak(22, 11, 0) を計算したところ、62.23 秒から 13.48 秒になりました。これは PC の性能だけではなく、Python3 のバージョンアップ (ver 3.10.12 --> 3.12.3) による実行速度の改善も寄与していると思われます。他の言語でも試してみようと思っています。
1月10日
●Google AI モード
いつもお世話になっている Google に AI モードが導入されました。日本語に対応したのが 2025 年 9 月なので、ご存じの方も多いと思います。AI モードはリンクを羅列するのではなく、AI が回答を直接生成する、という新しい機能です。ようするに、リンク先の Web サイトにいちいちアクセスしなくても、知りたい情報をまとめて得ることができるわけです。もちろん、AI の回答が 100 % 正しいわけではありませんが、このような機能を無料で利用できることに大変驚きました。
たとえば、「プログラミング言語 入門」を AI モードで検索すると、M.Hiroi の環境では冒頭で次のように表示されます。
『2026年現在、プログラミング学習は「AIをどう活用するか」が鍵となっています。初心者が今から始めるのにおすすめの言語と、学習のステップを簡潔に解説します。』
さらに、具体的な言語名を入力すると、その言語の特徴などが表示されます。たとえば Python と入力してみましょう。以下に示す内容が表示されます。
- Pythonで「できること」
- 初心者におすすめの学習ステップ(2026年版)
- おすすめの無料学習サイト
興味のある方は実際に試してみてください。それにしても AI の進歩は速いですね。凄い時代になったものだと驚愕しています。
1月3日
●Google Colaboratory
Google Colaboratory (通称 : Colab) は、Google が提供するブラウザ上で動作する無料の Python 実行環境です。Google アカウントとブラウザ (Chrome など) があれば、すぐに Python のプログラムを実行することができます。
Colab は GPU / TPU を無料で利用できるので、AI やディープラーニングのほうに目が行きがちですが、NumPy, SymPy, matplotlib など便利なライブラリもプリインストールされているので、import するだけで簡単に利用することができます。
なお、Colab の無料版には使用に制限がありますが、それを緩和した有料版も用意されています。学習目的で Colab を利用するのであれば、無料版の機能で十分なように思います。
遅ればせながら、実際に使ってみたところ、とても簡単に利用できることに大変驚きました。たとえば、SymPy で数式を表示してみましょう。次のプログラムを Colab のコードセルで実行します。
> import sympy as sy
sy.init_printing()
x = sy.Symbol('x')
f = x**2 + 2*x + 1
f
\(x^2 + 2x + 1\)
Colab の場合、init_printing() を実行すると、数式は MathJax を使って綺麗に表示されます。
グラフを表示することも簡単です。
> f1 = x**2 - 1
sy.plotting.plot(f1, (x, -2, 2))
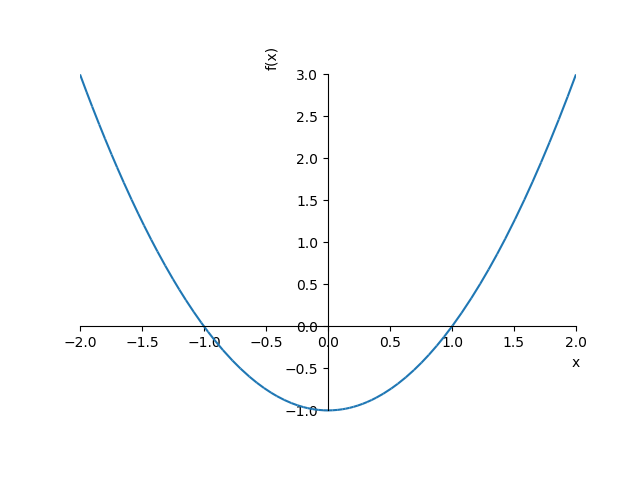
コードや実行結果はノートブックとして Google ドライブに保存され、あとから読み込むことができます。初めて Python を勉強するユーザーにとって、Colab はとても使いやすい実行環境だと思いました。
1月1日
あけましておめでとうございます
旧年中は大変お世話になりました
本年も M.Hiroi's Home Page をよろしくお願い申し上げます