Julia の基礎知識
●基本的な統計処理
- Julia には、統計処理用の関数が標準ライブラリ Statistics に用意されている
- 追加のインストールなしで、基本的な統計の計算が可能
- 統計学の基本については拙作のページ Algorithms with Python 番外編 統計学の基礎知識 を参照
- 以下に主な関数を示す
- sum(), 合計値
- minimum(), 最小値
- maximum(), 最大値
- mean(), 平均値
- median(), 中央値
- std(), 標準偏差
- var(), 分散
- corrected=false を指定すると、標本分散 (データ数 N とすると N で割る)
- デフォルトは不偏分散 (N - 1 で割る)
- cor(), 相関係数
- cov(), 共分散
- cumsum(), 累積和 (累積度数) を求める
- quantile(), 指定した割合の分位点を計算する
- 四分位数の例を示す
- 第 1 四分位数 quantile(data, 0.25)
データを小さい順に並べたとき、下から 1 / 4 番目にあたる値
- 中央値 (メディアン) quantile(data, 0.50)
データを半分に分ける 1 / 2 番目にあたる値
- 第 3 四分位数 quantile(data, 0.75)
データを小さい順に並べたとき、下から 3 / 4 番目にあたる値
- この他にも便利な関数が用意されている
- 詳細はリファレンスマニュアル Statistics を参照
julia> using Statistics
julia> height = [
148.7, 149.5, 133.7, 157.9, 154.2, 147.8, 154.6, 159.1, 148.2, 153.1,
138.2, 138.7, 143.5, 153.2, 150.2, 157.3, 145.1, 157.2, 152.3, 148.3,
152.0, 146.0, 151.5, 139.4, 158.8, 147.6, 144.0, 145.8, 155.4, 155.5,
153.6, 138.5, 147.1, 149.6, 160.9, 148.9, 157.5, 155.1, 138.9, 153.0,
153.9, 150.9, 144.4, 160.3, 153.4, 163.0, 150.9, 153.3, 146.6, 153.3,
152.3, 153.3, 142.8, 149.0, 149.4, 156.5, 141.7, 146.2, 151.0, 156.5,
150.8, 141.0, 149.0, 163.2, 144.1, 147.1, 167.9, 155.3, 142.9, 148.7,
164.8, 154.1, 150.4, 154.2, 161.4, 155.0, 146.8, 154.2, 152.7, 149.7,
151.5, 154.5, 156.8, 150.3, 143.2, 149.5, 145.6, 140.4, 136.5, 146.9,
158.9, 144.4, 148.1, 155.5, 152.4, 153.3, 142.3, 155.3, 153.1, 152.3
]
100-element Vector{Float64}:
... 略 ...
julia> sum(height)
15062.699999999999
julia> maximum(height)
167.9
julia> minimum(height)
133.7
julia> mean(height)
150.62699999999998
julia> median(height)
150.95
julia> quantile(height, 0.25)
146.75
julia> quantile(height, 0.50)
150.95
julia> quantile(height, 0.75)
154.525
julia> std(height)
6.465883348371474
julia> var(height)
41.8076474747475
julia> data1 = [
[4.6, 5.5], [0.0, 1.7], [6.4, 7.2], [6.5, 8.3],
[4.4, 5.7], [1.1, 1.1], [2.8, 4.1], [5.1, 6.7],
[3.4, 5.0], [5.8, 6.6], [5.7, 6.3], [5.5, 5.6],
[7.9, 8.7], [3.0, 3.6], [6.8, 8.2], [6.2, 6.2],
[4.0, 5.0], [8.6, 9.5], [7.5, 8.9], [1.3, 2.6],
[6.3, 7.4], [3.1, 5.0], [6.1, 8.2], [5.3, 6.6],
[3.9, 5.1], [5.8, 7.0], [2.6, 3.5], [4.8, 6.3],
[2.2, 2.9], [5.3, 6.9]
]
30-element Vector{Vector{Float64}}:
... 略 ...
julia> xs = [x[1] for x = data1]
30-element Vector{Float64}:
... 略 ...
julia> ys = [x[2] for x = data1]
30-element Vector{Float64}:
... 略 ...
julia> cor(xs, ys)
0.9684187227281572
julia> using StatsPlots
julia> histogram(height, title="Frequency", label="Frequency")
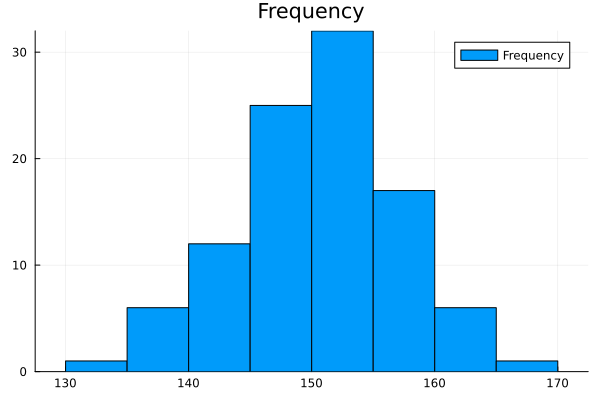 ヒストグラム
ヒストグラム
julia> boxplot(height)
julia> violin!(height)
julia> dotplot!(height)
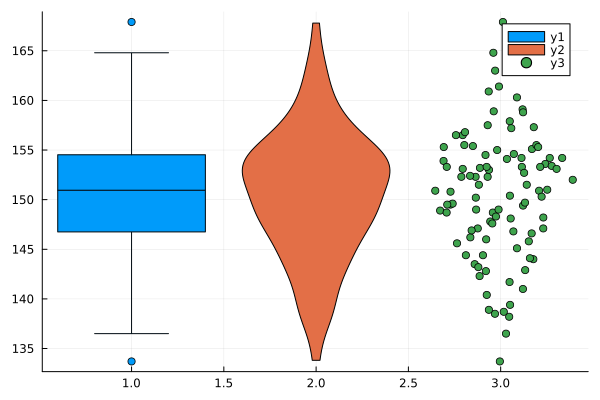 箱ひげ図, バイオリン図, ドットプロット
箱ひげ図, バイオリン図, ドットプロット
julia> scatter(xs, ys, title="Simple Scatter Plot", label="Data1")
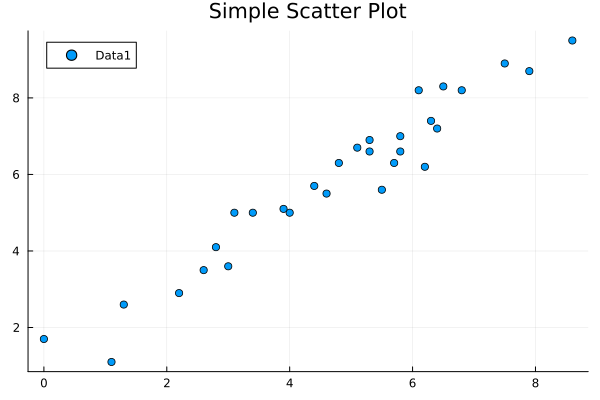 散布図
散布図
julia> scatter(xs, ys, smooth=true, title="Simple Scatter Plot", label="Data1")
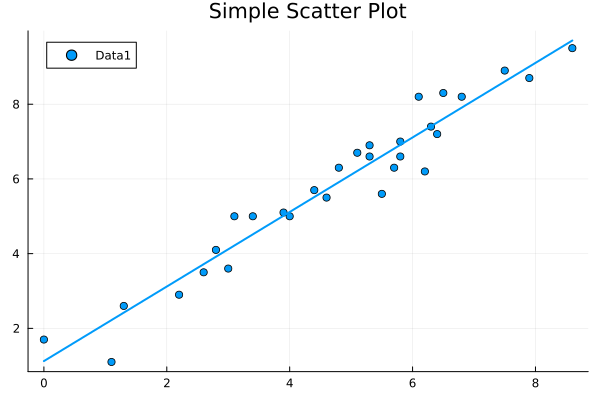 回帰直線
回帰直線
初版 2026 年 5 月 28 日
●StatsBase.jl
StatsBase.jlは、Julia で基礎的な統計計算やデータ分析を行うための主要なライブラリの一つです。Julia の標準ライブラリ Statistics よりもさらに高度で実用的な統計関数を幅広く提供しています。今回は StateBase.jl の基本的な使い方を簡単に説明します。
●インストール
Julia のパッケージモード (REPL で ] キーを押す) で次のコマンドを実行します。
(@v1.12) pkg> add StateBase
インストール終了後 st で状態を表示すると、M.Hiroi の環境では次のように表示されます。
(@v1.12) pkg> st
Status `~/.julia/environments/v1.12/Project.toml`
[336ed68f] CSV v0.10.16
[a93c6f00] DataFrames v1.8.2
[31c24e10] Distributions v0.25.125
[91a5bcdd] Plots v1.41.6
[2913bbd2] StatsBase v0.34.11
[f3b207a7] StatsPlots v0.15.8
[bd369af6] Tables v1.12.1
StatsBase v0.34.11 がインストールされました。インストールが終了したら、Backspace または Ctrl + C を押してください。通常の julia> プロンプトに戻ります。
●データの要約と基本統計量
StateBase.jl を使用する場合、最初に using StatsBase とします。これで標準ライブラリ Statistics の関数も使用することができます。それ以外にも、データの要約や統計量を求める便利な関数が追加されています。
- summarystats()
最小値、第1四分位数、中央値、平均値、第3四分位数、最大値を一括で求める
- geomean()
幾何平均を求める
- harmmean()
調和平均を求める
- skewness()
データの歪度 (分布の非対称性) を求める
- kurtosis()
尖度 (尖り度合い) を求める
- percentile()
任意のパーセンタイル (百分位数) を求める
幾何平均 (相乗平均) とは、複数のデータをすべて掛け合わせ、その個数に応じた累乗根(\(n\)乗根)を取ることで得られる平均値のことです。一般的な「足して個数で割る」算術平均とは異なり、倍率や比率、成長率など「掛け算で変化していくデータ」の平均を求めるときに使用されます。
\(n\) 個の正のデータ \(x_1, x_2, \dots, x_n\) の幾何平均 \(G\) は、以下の数式で表されます。
\(G=\sqrt[n]{x_{1}\times x_{2}\times \dots \times x_{n}}\)
調和平均 (harmonic mean) とは、「逆数の算術平均の逆数」として定義される平均の一種です。「時速」や「効率」など、単位あたりの比率を表すデータを平均する際に正しい結果を導き出すために使用されます。
\(n\) 個のデータ \(x_1, x_2, \dots, x_n\) の調和平均 \(H\) は、以下の数式で表されます。
\(H=\displaystyle \frac{n}{\frac{1}{x_{1}}+\frac{1}{x_{2}}+\dots +\frac{1}{x_{n}}}\)
歪度 (わいど, skewness) とは、統計学においてデータの分布が左右対称からどれだけ歪んでいるか (非対称性の度合い) を示す指標です。
- 正の値 (\(>0\))
右に裾が長い (山が左に偏る), 平均値 \(>\) 中央値
- ほぼゼロ (\(\approx 0\))
左右対称, 平均値 \(=\) 中央値
- 負の値 (\(<0\))
左に裾が長い (山が右に偏る), 平均値 \(<\) 中央値
データ (標本) の数を \(n\)、各データを \(x_{i}\)、平均値を \(m\)、標準偏差を \(s\) とするとき、歪度は以下の数式で定義されます。
\(歪度=\displaystyle \frac{1}{n}\sum _{i=1}^{n}\left(\frac{x_{i}-m}{s}\right)^{3}\)
尖度 (せんど, kurtosis) とは、データや確率変数の確率密度関数・頻度分布の「山の尖り具合」と「裾(テール)の広がり・重さ」を表す統計量です。データが正規分布からどの程度逸脱しているかを判断する客観的な目安として用いられます。
一般的に、尖度は正規分布の尖度 (3) を基準として評価されます。統計ツールでは、正規分布の尖度を 0 とする「超過尖度 (kurtosis-3)」が採用されていることが多いです。StatsBase.jl の関数 kurtosis() もそうです。
- 尖度 = 3 (超過尖度 = 0)
正規分布と同じ程度の尖り具合・裾の重さ
- 尖度 > 3 (超過尖度 > 0)
正規分布に比べて頂点が鋭く尖り、裾が太く重い (外れ値が多い) 分布
- 尖度 < 3 (超過尖度 < 0)
正規分布に比べて山が平坦で、裾が細く薄い (データが平均付近に広く散らばる) 分布
データ (標本) の数を \(n\)、各データを \(x_{i}\)、平均値を \(m\)、標準偏差を \(s\) とするとき、尖度は以下の数式で定義されます。
\(尖度=\displaystyle \frac{1}{n}\sum _{i=1}^{n}\left(\frac{x_{i}-m}{s}\right)^{4}\)
簡単な例を示しましょう。
julia> height = [
148.7, 149.5, 133.7, 157.9, 154.2, 147.8, 154.6, 159.1, 148.2, 153.1,
138.2, 138.7, 143.5, 153.2, 150.2, 157.3, 145.1, 157.2, 152.3, 148.3,
152.0, 146.0, 151.5, 139.4, 158.8, 147.6, 144.0, 145.8, 155.4, 155.5,
153.6, 138.5, 147.1, 149.6, 160.9, 148.9, 157.5, 155.1, 138.9, 153.0,
153.9, 150.9, 144.4, 160.3, 153.4, 163.0, 150.9, 153.3, 146.6, 153.3,
152.3, 153.3, 142.8, 149.0, 149.4, 156.5, 141.7, 146.2, 151.0, 156.5,
150.8, 141.0, 149.0, 163.2, 144.1, 147.1, 167.9, 155.3, 142.9, 148.7,
164.8, 154.1, 150.4, 154.2, 161.4, 155.0, 146.8, 154.2, 152.7, 149.7,
151.5, 154.5, 156.8, 150.3, 143.2, 149.5, 145.6, 140.4, 136.5, 146.9,
158.9, 144.4, 148.1, 155.5, 152.4, 153.3, 142.3, 155.3, 153.1, 152.3
]
100-element Vector{Float64}:
... 省略 ...
julia> summarystats(height)
Summary Stats:
Length: 100
Missing Count: 0
Mean: 150.627000
Std. Deviation: 6.465883
Minimum: 133.700000
1st Quartile: 146.750000
Median: 150.950000
3rd Quartile: 154.525000
Maximum: 167.900000
julia> percentile(height, 25)
146.75
julia> percentile(height, 50)
150.95
julia> percentile(height, 75)
154.525
julia> geomean([1, 2, 3])
1.8171205928321397
julia> (1 * 2 * 3)^(1 / 3)
1.8171205928321397
julia> harmmean([1, 2, 3])
1.6363636363636365
julia> 3 / (1 + (1 / 2) + (1 / 3))
1.6363636363636365
julia> skewness(height)
-0.11463683645167476
julia> kurtosis(height)
0.037582921776352585
●重み付き統計量
重み付き統計量とは、データの重要度、信頼度、あるいは母集団の構成比に応じた「重み (ウェイト:\(w_{i}\))」を掛け合わせて算出する統計量のことです。一般的な統計量 (算術平均など) はすべてのデータを平等に扱いますが、データごとにサンプルの大きさや測定精度が異なる場合、重み付き統計量を用いることでより現実に即した正確な分析が可能になります。
StatsBase.jl を使用すると、重み付き平均、重み付き分散、重み付き共分散などの統計量を簡単に計算することができます。なお、計算を行うには、重み (ウエイト) を通常の配列のまま渡すのではなく、目的に応じた専用の重みベクトルオブジェクトに変換して関数に渡す必要があります。
- 関数 weights() などで重み配列を重みベクトルに変換する
- 統計関数 (mean() や var() など) の引数にデータと重みベクトルを渡す
主要な重み付き統計関数を以下に示します。
- mean(v, w): 重み付き平均
- var(v, w): 重み付き分散
- std(v, w): 重み付き標準偏差
- cov(x, y, w): 重み付き共分散
- cor(x, y, w): 重み付き相関係数
- median(v, w): 重み付き中央値
- quantile(v, w, p): 重み付き分位数(p には 0.25 などを指定)
var() や std() などの関数には、不偏分散 (自由度補正) を行うかどうかのオプション corrected があります。重みの種類によって、corrected=true のときの不偏補正の挙動が変わるようです。
重みベクトルを生成する主な関数を以下に示します。
- weights(v)
最も汎用的な重み。特に統計的な意図を特定しない場合に使用。
- fweights(v)
頻度重み (Frequency weights)。各要素が「何回繰り返し現れたか」を表す整数値。
- aweights(v)
分析重み (Analytic weights)。各要素の観測値の「精度の高さ (逆分散など)」を表す。
- pweights(v)
確率重み (Probability weights)。サンプリングデザイン(調査設計)において、その要素が選ばれる「確率の逆数」を表す。
詳しい説明は StatsBase.jl の ドキュメント をお読みくださいませ。
ここでは weight() と fweight() の簡単な使用例を示します。
julia> using StatsBase
julia> x = [1.0, 2.0, 3.0, 4.0]
4-element Vector{Float64}:
1.0
2.0
3.0
4.0
julia> w = weights([0.1, 0.2, 0.4, 0.3])
4-element Weights{Float64, Float64, Vector{Float64}}:
0.1
0.2
0.4
0.3
julia> mean(x)
2.5
julia> mean(x, w)
2.9000000000000004
julia> (1 * 0.1 + 2 * 0.2 + 3 * 0.4 + 4 * 0.3) / 1.0
2.9000000000000004
julia> var(x, w, corrected=false)
0.8900000000000001
julia> var(x)
1.6666666666666667
julia> std(x, w, corrected=false)
0.9433981132056605
julia> std(x)
1.2909944487358056
fweights() は、データが「同じ値が何回繰り返して出現したか」を表す場合に使用する重みベクトルです。例えば、データ [10, 20] に対して重み [3, 2] を指定した場合、それは内部的に [10, 10, 10, 20, 20] という 5 つのデータが存在することと同じになります。簡単な例を示しましょう。
julia> x = [10, 20]
2-element Vector{Int64}:
10
20
julia> fw = fweights([3, 2])
2-element FrequencyWeights{Int64, Int64, Vector{Int64}}:
3
2
julia> mean(x, fw)
14.0
julia> mean([10, 10, 10, 20, 20])
14.0
julia> var(x, fw)
24.0
julia> var(x, fw, corrected=true)
30.0
julia> var([10, 10, 10, 20, 20], corrected=false)
24.0
julia> var([10, 10, 10, 20, 20], corrected=true)
30.0
julia> std(x, fw, corrected=false)
4.898979485566356
julia> std(x, fw, corrected=true)
5.477225575051661
julia> std([10, 10, 10, 20, 20], corrected=false)
4.898979485566356
julia> std([10, 10, 10, 20, 20], corrected=true)
5.477225575051661
fweights() の場合、corrected=true とすると不偏分散を計算します。このときの分母は sum(fw) - 1 になります。false にすると標本分散を計算するので、分母は sum(fw) になります。
●サンプリング
StatsBase.jl を用いると、データからのランダム抽出を高度に制御することができます。
- sample(x, [weights], n; replace=true/false)
- n : 抽出するデータ数
- replace=true (デフォルト) : 重複あり (復元抽出)
- replace=false : 重複なし (非復元抽出)
- weights : 重みの指定
- sample!(x, y)
メモリ効率を意識して、既存の配列 y にサンプリング結果を直接書き込む
簡単な例を示しましょう。
julia> using StatsBase
julia> items = ["apple", "banana", "orange", "grape"]
4-element Vector{String}:
"apple"
"banana"
"orange"
"grape"
julia> sample(items)
"banana"
julia> sample(items)
"orange"
julia> sample(items)
"apple"
julia> sample(items, 3)
3-element Vector{String}:
"apple"
"apple"
"grape"
julia> sample(items, 3, replace=false)
3-element Vector{String}:
"banana"
"apple"
"grape"
特定の要素が選ばれやすくなるよう、「重み(ウェイト)」を設定することができます。重みの指定には weights() や pweights() などの関数を使います。pweight() には要素の出現確率を格納した配列を渡します。
julia> w = pweights([0.6, 0.2, 0.1, 0.1])
4-element ProbabilityWeights{Float64, Float64, Vector{Float64}}:
0.6
0.2
0.1
0.1
julia> sample(items, w, 10)
10-element Vector{String}:
"orange"
"apple"
"apple"
"apple"
"banana"
"banana"
"orange"
"orange"
"apple"
"apple"
julia> sample(items, w, 10)
10-element Vector{String}:
"apple"
"banana"
"apple"
"apple"
"grape"
"banana"
"apple"
"apple"
"apple"
"grape"
replace=false を指定すると、一度選ばれた要素を除外していくこともできます。
julia> sample(items, w, 2, replace=false)
2-element Vector{String}:
"apple"
"banana"
julia> sample(items, w, 2, replace=false)
2-element Vector{String}:
"apple"
"banana"
大量のサンプリングを何度も行う場合、新しくメモリを確保するのではなく、用意しておいた配列に結果を直接書き込む (破壊的修正) ことで処理を高速化できます。これには関数 sample!() を使います。
julia> x = 1:10
1:10
julia> y = Vector{Int}(undef, 4)
4-element Vector{Int64}:
137127179485008
0
0
0
julia> sample!(x, y)
4-element Vector{Int64}:
7
1
2
6
julia> y
4-element Vector{Int64}:
7
1
2
6
julia> sample!(x, y)
4-element Vector{Int64}:
2
3
9
3
julia> y
4-element Vector{Int64}:
2
3
9
3
●計数とヒストグラム
StatsBase.jl には、データの出現回数を数えるための便利な関数が用意されています。主な関数を以下に示します。
- countmap(data)
最も汎用的で、文字列、記号 (Symbol)、整数など任意の型の要素の出現回数をカウントして Dict (辞書型) で返す
- counts(data, k)
1 から k までの整数の出現回数をカウントし、結果を大きさ k のベクタに格納して返す
範囲外のデータは無視される
- counts(data, min : max)
min から max までの整数の出現回数をカウントし、 結果を大きさ max - min + 1 のベクタに格納して返す
範囲外のデータは無視される
- proportions(data, ...)
各要素の出現回数ではなく、出現割合 (比率) を計算して返す
counts() と同様に範囲を指定できる
- addcounts!(vec, data, ...)
カウントした結果を、新しく配列を作らずに既存の配列 vec に破壊的に加算する
簡単な使用例を示しましょう。
julia> items = ["apple", "banana", "orange", "grape"]
4-element Vector{String}:
"apple"
"banana"
"orange"
"grape"
julia> w = pweights([0.6, 0.2, 0.1, 0.1])
4-element ProbabilityWeights{Float64, Float64, Vector{Float64}}:
0.6
0.2
0.1
0.1
julia> a = sample(items, w, 10)
10-element Vector{String}:
"orange"
"apple"
"apple"
"apple"
"apple"
"orange"
"apple"
"apple"
"apple"
"banana"
julia> countmap(a)
Dict{String, Int64} with 3 entries:
"orange" => 2
"banana" => 1
"apple" => 7
julia> b = rand(1:10, 16)
16-element Vector{Int64}:
2
7
4
3
6
10
6
10
7
6
6
10
1
4
8
5
julia> counts(b, 10)
10-element Vector{Int64}:
1
1
1
2
1
4
2
1
0
3
julia> counts(b, 5)
5-element Vector{Int64}:
1
1
1
2
1
counts(b, 3:7)
5-element Vector{Int64}:
1
2
1
4
2
julia> proportions(b, 10)
10-element Vector{Float64}:
0.0625
0.0625
0.0625
0.125
0.0625
0.25
0.125
0.0625
0.0
0.1875
julia> sum(proportions(b, 10))
1.0
julia> proportions(b, 3:7)
5-element Vector{Float64}:
0.0625
0.125
0.0625
0.25
0.125
julia> sum(proportions(b, 3:7))
0.625
julia> v = [10, 10, 10, 10]
4-element Vector{Int64}:
10
10
10
10
julia> z = [1, 1, 2, 1, 2, 3, 1, 2, 3, 4]
10-element Vector{Int64}:
1
1
2
1
2
3
1
2
3
4
julia> addcounts!(v, z, 1: 4)
4-element Vector{Int64}:
14
13
12
11
julia> v
4-element Vector{Int64}:
14
13
12
11
StatsBase.jl でヒストグラムを扱うには、関数 fit(Histogram, data) を使用します。
- fit(Histogram, data)
データの分布からヒストグラムのビン (区切り) と度数を自動計算する
- nbins = n : 大まかなビンの数を指定する
- edges = range or vector : ビンの境界を厳密に指定する
簡単な例を示しましょう。
julia> height
100-element Vector{Float64}:
... 略 ...
julia> h = fit(Histogram, height)
Histogram{Int64, 1, Tuple{StepRangeLen{Float64, Base.TwicePrecision{Float64}, Base.TwicePrecision{Float64}, Int64}}}
edges:
130.0:5.0:170.0
weights: [1, 6, 12, 25, 32, 17, 6, 1]
closed: left
isdensity: false
julia> h.edges
(130.0:5.0:170.0,)
julia> h.weights
8-element Vector{Int64}:
1
6
12
25
32
17
6
1
●順位相関係数
StatsBase.jl で順位相関係数を計算するには、関数 corspearman(), corkendall() を使います。順位相関係数の説明は拙作のページ Algorithms with Python 番外編 統計学の基礎知識 [3] をお読みくださいませ。
- corspearman(x, y), スピアマンの順位相関係数
- corkendall(x, y), ケンドールの順位相関係数
これらの関数は内部で自動的に順位付けを行うため、関数に渡す前のデータは生の数値のままで問題ありません。
簡単な使用例を示します。
julia> using StatsBase
julia> data1 = [
[4.6, 5.5], [0.0, 1.7], [6.4, 7.2], [6.5, 8.3],
[4.4, 5.7], [1.1, 1.1], [2.8, 4.1], [5.1, 6.7],
[3.4, 5.0], [5.8, 6.6], [5.7, 6.3], [5.5, 5.6],
[7.9, 8.7], [3.0, 3.6], [6.8, 8.2], [6.2, 6.2],
[4.0, 5.0], [8.6, 9.5], [7.5, 8.9], [1.3, 2.6],
[6.3, 7.4], [3.1, 5.0], [6.1, 8.2], [5.3, 6.6],
[3.9, 5.1], [5.8, 7.0], [2.6, 3.5], [4.8, 6.3],
[2.2, 2.9], [5.3, 6.9]
]
30-element Vector{Vector{Float64}}:
... 略 ...
julia> xs = [x[1] for x = data1]
30-element Vector{Float64}:
... 略 ...
julia> ys = [x[2] for x = data1]
30-element Vector{Float64}:
... 略 ...
julia> cor(xs, ys)
0.9684187227281572
julia> corspearman(xs, ys)
0.9569091784714749
julia> corkendall(xs, ys)
0.8607981309614495
相関係数を計算するだけでなく、データそのものの「順位」を取得したい場合は、StatsBase.jl に用意されている以下の関数を使います。同順位 (タイ記録) がある場合の処理方法によって関数が異なります。
- ordinalrank(x): 同順位があっても、出現順に一意の順位(1, 2, 3 ...)を割り当てる
- competerank(x): 一般的な順位付け(1位、2位、2位、4位 ...)を行う
- denserank(x): 同順位の次の順位を飛ばさずに詰める (1位、2位、2位、3位 ...)
- tiedrank(x): 同順位がある場合、それらが占める順位の平均値を割り当てる (1位、2.5位、2.5位、4位 ...)
統計解析処理で最も広く使われる形式が tiedrank() です。簡単な実行例を示します。
julia> for x in competerank(xs) print(x, " ") end
13 1 25 26 12 2 6 15 9 20 19 18 29 7 27 23 11 30 28 3 24 8 22 16 10 20 5 14 4 16
julia> for x in tiedrank(xs) print(x, " ") end
13.0 1.0 25.0 26.0 12.0 2.0 6.0 15.0 9.0 20.5 19.0 18.0 29.0 7.0 27.0 23.0 11.0 30.0
28.0 3.0 24.0 8.0 22.0 16.5 10.0 20.5 5.0 14.0 4.0 16.5
この他にも StatsBase.jl には便利な関数がいろいろ用意されています。興味のある方は StateBase.jl の ドキュメント をお読みくださいませ。