ガベージコレクション
●はじめに
『お気楽C言語プログラミング超入門』の番外編です。本ページでは、超入門で取り上げることができなかったデータ構造やアルゴリズムなど、いろいろなプログラムをC言語で作ってみようと思っております。少々難しい話になるかもしれませんが、よろしければお付き合いくださいませ。
今回は「ガベージコレクション (garbage collection: GC)」の基本的な仕組みを簡単に説明します。そして、C/C++用のガベージコレクタ Boehm GC を紹介します。
●ガベージコレクションの基礎知識
簡単な例として、「連結リスト (セル)」のガベージコレクションを考えてみます。説明の都合上、セルは複数個まとめて malloc で確保することにします。これを「セル領域」と呼ぶことにします。そして、下図のように未使用のセルをつないで管理します。
cell_free --> [ | ] --> [ | ] --> ... --> [ | ] --> NULL
図 : 未使用セルのリンケージ
cell_free は未使用のセルを保持する変数です。未使用のセルはリストで管理します。これを「フリーリスト」と呼ぶことにします。
ガベージコレクションの基本的な動作は、使用しているセルと不要になったセルを区別して、不要になったセルを回収することです。セルはプログラムのいろいろな場所から参照されます。スタック上に確保された局所変数や静的に確保された外部変数、レジスタや他のセルからも参照されます。
このように、セルを参照している領域はいろいろありますが、セル以外の領域をまとめて「ルート (root)」と呼ぶことにします。すると、ルートから参照されているセルはプログラムで使用中のセルと考えることができます。そして、使用中のセルからたどることができるセルも、また使用中のセルと考えることができます。ルートからたどることができないセルを「到達不能」であるといいます。到達不能なセルは「不要になったセル」と判断することができます。
●リファレンスカウント法
到達不能なセルが生じたことを検出する簡単な方法は、各セルに「参照回数」を持たせることです。変数やセルのメンバ変数などで、あるセルのアドレスをセットしたとき、そのセルの参照回数を +1 します。アドレスを書き換えたときは、元のセルの参照回数を -1 します。そして、参照回数が 0 になったならば、そのセルは到達不能になったので回収します。これを「リファレンスカウント法 (Reference counting)」といいます。
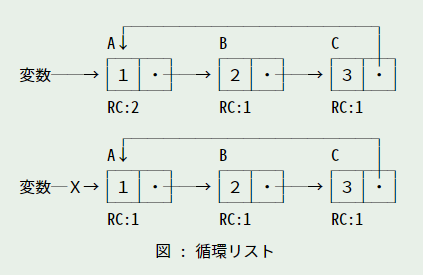
リファレンスカウント法には大きな欠点があります。循環リストがある場合、参照回数だけでは到達不能なセルを検出することができないのです。次の図を見てください。
ある変数がセル A を参照している状態で、各セルの参照回数を RC で表しています。セル A は変数とセル C から参照されているので RC は 2 になります。セル B と C の RC は 1 です。この状態で変数の値を書き換えて、セル A の RC が -1 されたとします。
すると、A の RC は 1 になりますが 0 にはならないので、A を回収することはできません。セル B はセル A だけから参照されていますが、セル A が生き残っているので、RC は 1 のままです。セル C も同様です。つまり、循環リストがあると、ルートから到達できない状態になっても参照回数が 0 にならないのです。
このため、リファレンスカウント法を使う場合は、到達不能な循環リストを検出するため、他のアルゴリズムと組み合わせることがあります。たとえば、スクリプト言語 Python の GC はリファレンスカウント法が基本ですが、循環したデータ構造を検出して回収するため、アルゴリズムが異なる GC も使っています。
●マークスイープ法
もう一つ基本的な方法に「マークスイープ法 (mark sweep)」があります。マークスイープ法は、未使用なセルがなくなった時点で GC を起動して、到達不能になったセルをいっきに回収する方法です。まず、ルートからたどることができるセルすべてに印をつける作業 (Mark) を行います。それから、セル領域全体を探索して、マークの付いていないセルを回収する作業 (Sweep) を行います。このように、2 段階の手順をふんで GC を実行することからマークスイープ法と呼ばれています。
ただし、C言語やC++でマークスイープ法を実行する場合、スタック領域やレジスタに格納されている値が、たんなる数値なのかセルへのポインタなのか区別することができません。このため、曖昧な値はセルとして判定することにします。これを「保守的な GC (conservative GC)」といいます。
マークするとき、値がセル領域の範囲外あれば数値と判定することができます。また、セルが偶数番地から配置されているとすると、セル領域の範囲内であっても値が奇数であれば、それも数値として判定することができます。とりあえず、それ以外の値はセルとして判定するのが保守的な GC なのです。
当然ですが、保守的な GC は数値としてスタックに詰まれたデータを間違ってセルと判定することがあります。その数値に対応するセルが到達不能な場合、そのセルを回収することはできません。ですが、その頻度がそれほど多くなければ、プログラムの実行に大きな影響を及ぼすことは少ないと考えられます。今回紹介する Bohem GC は保守的な GC を採用しています。
●Boehm GC の使い方
Boehm GC はC/C++ 用の「ガベージコレクタ (garbage collector)」です。malloc を GC_MALLOC に変えるだけで、不要になったメモリを自動的に回収してくれます。最近のプログラミング言語、特に関数型言語やスクリプト言語では、当然のように GC が実装されていますが、Boehm GC を使っている処理系もあります。たとえば、M.Hiroi も愛用している Gauche (Scheme) がそうです。
Debian 系の Linux であれば、次のコマンドで Boehm GC をインストールすることができます。
sudo apt install libgc-dev
基本的な使い方は簡単です。ヘッダファイル gc.h をインクルードします。そして、malloc, calloc のかわりに GC_MALLOC (内部にポインタを含まない場合は GC_MALLOC_ATOMIC) を、realloc のかわりに GC_REALLOC を使い、プログラムから free を削除します。あとは、コンパイルするときに -l オプションで gc を指定する (-lgc とする) だけです。
Boehm GC については LinuxC, LinuxC | GC を参考にさせていただきました。有益な情報を公開されている khondalit さんに感謝いたします。
●連結リストによる順列の生成
それでは簡単な例題として、連結リストを使って順列を生成するプログラムを作ってみましょう。最初にセルを定義します。
リスト : Boehm GC の使用例
#include <stdio.h>
#include <gc.h>
// セルの定義
typedef struct cell {
int item;
struct cell *next;
} Cell;
// セルの生成
Cell *make_cell(int x, Cell *next)
{
Cell *cp = GC_MALLOC(sizeof(Cell));
cp->item = x;
cp->next = next;
return cp;
}
構造体 Cell はポインタを含んでいるので、メモリの取得には GC_MALLOC を使います。GC_MALLOC_ATOMIC を使ってはいけません。
次に、順列を生成するプログラムを作ります。
リスト : 順列の生成
// セルの表示
void print_cell(Cell *cp)
{
for (; cp != NULL; cp = cp->next)
printf("%d ", cp->item);
printf("\n");
}
// x と等しいセルを削除
Cell *remove_cell(int x, Cell *cp)
{
if (cp == NULL)
return NULL;
else if (cp->item == x)
return remove_cell(x, cp->next);
else
return make_cell(cp->item, remove_cell(x, cp->next));
}
// 順列の生成
void perm(Cell *nums, Cell *a)
{
if (nums == NULL)
print_cell(a);
else
for (Cell *cp = nums; cp != NULL; cp = cp->next) {
perm(remove_cell(cp->item, nums), make_cell(cp->item, a));
}
}
関数 print_cell は連結リストを表示します。関数 remove は引数 x と等しい要素を削除します。remove は引数のリストを破壊的に修正せず、新しいリストを生成していることに注意してください。
関数 perm は数字のリスト nums から数字を順番に選択します。そして、nums から選んだ数字を削除し、それを累積変数 a のリストに追加して perm を再帰呼び出しします。これで nums に格納された数字の順列を生成することができます。
関数型言語でリストを操作するときは、このように引数のリストを破壊せずに新しいリストを生成することがよく行われます。当然ですが、セルを消費するだけではメモリ不足になってしまいます。GC があると、不要になったメモリを自動的に回収してくれるので、このようなプログラムでも正常に動作します。
それでは実際に試してみましょう。次のテストを行ってみました。
リスト : 簡単なテスト
// 数列の生成
Cell *iota(int n, int m)
{
Cell *a = NULL;
while (n <= m) {
a = make_cell(m, a);
m--;
}
return a;
}
int main(void)
{
perm(iota(1, 9), NULL);
printf("%lu\n", GC_gc_no);
return 0;
}
関数 iota は n から m までの数値を格納したリストを生成します。perm(iota(1, 9), NULL) で、1 から 9 までの順列を生成することができます。このプログラムを実行して、タスクマネージャなどでメモリの使用量をチェックすると、大量のメモリを消費せずにプログラムが動作していることがわかります。それから、GC_gc_no [*1] には GC を行った回数が記録されています。M.Hiroi の環境では 494 回 GC が起動されました。
それにしても、Boehm GC はとても便利ですね。興味のある方はいろいろ試してみてください。
-- note --------
[*1] Boehm GC ver 8.0.6 の場合、GC_gc_no は非推奨になりました。GC_gc_no を使用するとワーニングが表示されます。
●プログラムリスト
リスト : Boehm GC の簡単なテスト
#include <stdio.h>
#include <gc.h>
// セルの定義
typedef struct cell {
int item;
struct cell *next;
} Cell;
// セルの生成
Cell *make_cell(int x, Cell *next)
{
Cell *cp = GC_MALLOC(sizeof(Cell));
cp->item = x;
cp->next = next;
return cp;
}
// セルの表示
void print_cell(Cell *cp)
{
for (; cp != NULL; cp = cp->next)
printf("%d ", cp->item);
printf("\n");
}
// x と等しいセルを削除
Cell *remove_cell(int x, Cell *cp)
{
if (cp == NULL)
return NULL;
else if (cp->item == x)
return remove_cell(x, cp->next);
else
return make_cell(cp->item, remove_cell(x, cp->next));
}
// 順列の生成
void perm(Cell *nums, Cell *a)
{
if (nums == NULL)
print_cell(a);
else
for (Cell *cp = nums; cp != NULL; cp = cp->next) {
perm(remove_cell(cp->item, nums), make_cell(cp->item, a));
}
}
// 数列の生成
Cell *iota(int n, int m)
{
Cell *a = NULL;
while (n <= m) {
a = make_cell(m, a);
m--;
}
return a;
}
int main(void)
{
perm(iota(1, 9), NULL);
printf("%lu\n", GC_gc_no);
return 0;
}
初版 2015 年 4 月 11 日
改訂 2023 年 4 月 8 日
続・電卓プログラムの作成
電卓プログラムの作成 では、構文解析のときに式の計算をいっしょに行っていましたが、今後の拡張を考えて、今回は簡単な「構文木」を組み立てるように修正します。また、メモリ領域の取得には Boehm GC を使いましょう。不要になったメモリを自動的に回収してくれるので、メモリ管理はとても簡単になります。
●構文木の定義
最初に、構文木 (式) を表すデータ型 Expr を定義します。数式は二分木で表すことができるので、Expr は二分木と同じような構造になります。
リスト : 構文木の定義
// タグ
enum {Num, Add2, Sub2, Mul2, Div2, Add1, Sub1};
// 構文木
typedef struct expr {
int tag;
union {
double num; // 数値
struct { // 構文木
struct expr *left;
struct expr *right;
};
};
} Expr;
構造体 Expr のメンバ変数 tag がデータの種別を表すタグです。Num が数値、Add2 (+), Sub2 (-), Mul2 (*), Div2 (/) が二項演算子、Add1 (+), Sub1 (-) が単項演算子です。単項演算子は式を 1 つメンバ変数 left に、二項演算子は式を 2 つ left と right に格納します。left が左辺の式、right が右辺の式を表します。union は無名の共用体になっていることに注意してください。
簡単な例を示しましょう。ここでは、Expr を (op, left, right) で表すことにします。
1 + 2 - 3 => (Sub2, (Add2, 1, 2), 3)
1 + 2 * 3 => (Add2, 1, (Mul2, 2, 3))
1 + -2 * 3 => (Add2, 1, (Mul2, (Sub1, 2, NULL), 3))
1 + 2 * 3 は * の優先順位が高いので、(Mul2, ...) が (Add2, ...) の子になります。
次は構文木を生成する関数を作ります。
リスト ; 構文木の生成
// 数値の生成
Expr *make_number(double n)
{
Expr *e = GC_MALLOC_ATOMIC(sizeof(Expr));
e->tag = Num;
e->num = n;
return e;
}
// 単項演算子の生成
Expr *make_op1(int op, Expr *e1)
{
Expr *e = GC_MALLOC(sizeof(Expr));
e->tag = op;
e->left = e1;
e->right = NULL;
return e;
}
// 二項演算子の生成
Expr *make_op2(int op, Expr *e1, Expr *e2)
{
Expr *e = GC_MALLOC(sizeof(Expr));
e->tag = op;
e->left = e1;
e->right = e2;
return e;
}
make_number は数値を格納する節を生成します。メンバ変数にポインタが含まれていないので、メモリの取得は GC_MALLOC_ATOMIC で行います。make_op1 は単項演算子を表す節を生成します。メンバ変数 left に引数 e1 を、right には NULL をセットします。make_op2 が二項演算子を表す節を生成します。メンバ変数 left に引数 e1 を、right に引数 e2 をセットします。どちらの関数もメンバ変数にポインタがあるので、メモリ領域の取得は GC_MALLOC で行います。
●構文解析の修正
次は構文解析のプログラムを修正します。
リスト : 構文解析
// プロトタイプ宣言
Expr *expression(void);
Expr *term(void);
Expr *factor(void);
// 式
Expr *expression(void)
{
Expr *e = term();
while (true) {
switch (token) {
case Add:
get_token();
e = make_op2(Add2, e, term());
break;
case Sub:
get_token();
e = make_op2(Sub2, e, term());
break;
default:
return e;
}
}
}
// 項
Expr *term(void)
{
Expr *e = factor();
while (true) {
switch (token) {
case Mul:
get_token();
e = make_op2(Mul2, e, factor());
break;
case Div:
get_token();
e = make_op2(Div2, e, factor());
break;
default:
return e;
}
}
}
// 因子
Expr *factor(void)
{
switch (token) {
case Lpar:
get_token();
Expr *e = expression();
if (token == Rpar)
get_token();
else
error("')' expected");
return e;
case Number:
get_token();
return make_number(value);
case Add:
get_token();
return make_op1(Add1, factor());
case Sub:
get_token();
return make_op1(Sub1, factor());
default:
error("unexpected token");
}
}
関数 expression, term, factor の返り値は、データ型が Expr * になります。expression の場合、トークンが Add, Sub であれば、式 e と term の返り値を make_op2 に渡して、構文木を組み立てます。term も同様に、トークンが Mul, Div であれば構文木を組み立てます。
factor の場合、トークンが Lpar であれば expression を再帰呼び出しして、変数 e にセットします。そして、右カッコで閉じられていることを確認してから式 e を返します。トークンが Number の場合は、外部変数 value の値を make_number に渡して、数値を格納した節を生成して返します。Add と Sub の場合は make_op1 で単項演算子を表す節を生成して返します。
●式の評価
次は構文木を評価して式の値を求める関数 eval を作りましょう。次のリストを見てください。
リスト : 式の計算
double eval(Expr *e)
{
switch (e->tag) {
case Num: return e->num;
case Add1: return eval(e->left);
case Sub1: return -eval(e->left);
case Add2: return eval(e->left) + eval(e->right);
case Sub2: return eval(e->left) - eval(e->right);
case Mul2: return eval(e->left) * eval(e->right);
case Div2: return eval(e->left) / eval(e->right);
default:
fprintf(stderr, "invalid operator %d\n", e->tag);
exit(1);
}
}
eval は再帰呼び出しを使うと簡単です。引数 e のタグが Num であれば、e->num を返します。タグが Add1 であれば eval(e->left) の値を返します。Sub1 であれば -eval(left) の値を返します。なお、単項演算子 + は、構文解析の段階で削除することもできます。二項演算子の場合、式 e->left と e->right を eval で評価してから、タグに対応した計算を行うだけです。
●式の入力と評価の修正
最後に式を入力して評価する処理を修正します。次のリストを見てください。
リスト : 式の入力と評価
void toplevel(void)
{
Expr *e = expression();
if (token == Semic) {
printf("=> %.16g\nCalc> ", eval(e));
fflush(stdout);
} else {
error("invalid token");
}
}
関数 toplevel は expression を実行して入力された数式を解析します。そのあと、式がセミコロン (Semic) で終了していることを確認します。次に、expression の返り値 e を eval で評価して、入力された数式を計算し、その結果を表示します。
●実行例
それでは簡単な実行例を示します。
Calc> 1 + 2 + 3 + 4;
=> 10
Calc> (1 + 2) * (3 + 4);
=> 21
Calc> 123456789 * 123456789;
=> 1.524157875019052e+16
Calc> 1.11111111 * 1.11111111;
=> 1.234567898765432
Calc> 3 / 2;
=> 1.5
Calc> 1.23456789 / 1.1111111;
=> 1.111111112111111
今回はここまでです。次回は変数と組込み関数の機能を追加します。
●参考文献
- 松田晋, 『実践アルゴリズム戦略 解法のテクニック 再帰降下型構文解析』, C MAGAZINE 1992 年 9 月号, ソフトバンク
- 水野順, 『スクリプト言語を作ろう』, C MAGAZINE 2000 年 5 月号, ソフトバンク
- 松浦健一郎, 『コンパイラの作成』, C MAGAZINE 2003 年 1 月号, ソフトバンク
- 高田昌之, 『インタプリタ進化論』, CQ出版社, 1992
- 久野靖, 『言語プロセッサ』, 丸善株式会社, 1993
●プログラムリスト
//
// calc3.c : 電卓プログラム (構文木を組み立てる)
//
// Copyright (C) 2015-2013 Makoto Hiroi
//
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <stdbool.h>
#include <setjmp.h>
#include <gc.h>
// タグ
enum {Num, Add2, Sub2, Mul2, Div2, Add1, Sub1};
// 構文木
typedef struct expr {
int tag;
union {
double num; // 数値
struct { // 構文木
struct expr *left;
struct expr *right;
};
};
} Expr;
// 数値の生成
Expr *make_number(double n)
{
Expr *e = GC_MALLOC_ATOMIC(sizeof(Expr));
e->tag = Num;
e->num = n;
return e;
}
// 単項演算子の生成
Expr *make_op1(int op, Expr *e1)
{
Expr *e = GC_MALLOC(sizeof(Expr));
e->tag = op;
e->left = e1;
e->right = NULL;
return e;
}
// 二項演算子の生成
Expr *make_op2(int op, Expr *e1, Expr *e2)
{
Expr *e = GC_MALLOC(sizeof(Expr));
e->tag = op;
e->left = e1;
e->right = e2;
return e;
}
// トークン
enum {Eof, Number, Add, Sub, Mul, Div, Lpar, Rpar, Semic, Others};
// 外部変数
int ch; // 記号
int token; // トークン
double value; // 数値
jmp_buf err; // エラー脱出用
// トークン名
char *token_name[] = {
"EOF",
"Number",
"+",
"-",
"*",
"/",
"(",
")",
";",
"Others",
};
// 記号の先読み
void nextch(void)
{
ch = getchar();
}
// 先読み記号の取得
int getch(void)
{
return ch;
}
// エラー
_Noreturn
void error(char *mes)
{
fprintf(stderr, "%s, %s\n", mes, token_name[token]);
longjmp(err, 1);
}
#define SIZE 1024
// 整数部をバッファに格納する
int get_fixnum(char *buff, int i)
{
while (isdigit(getch())) {
buff[i++] = getch();
nextch();
}
return i;
}
// 数値を求める
double get_number(void)
{
char buff[SIZE + 1];
char *err;
int i = get_fixnum(buff, 0);
if (getch() == '.') {
buff[i++] = getch();
nextch();
i = get_fixnum(buff,i);
}
if (getch() == 'e' || getch() == 'E') {
buff[i++] = getch();
nextch();
if (getch() == '+' || getch() == '-') {
buff[i++] = getch();
nextch();
}
i = get_fixnum(buff, i);
}
buff[i] = '\0';
double value = strtod(buff, &err);
if (*err != '\0')
error("get_number: not Number\n");
return value;
}
// トークンの切り分け
void get_token(void)
{
// 空白文字の読み飛ばし
while (isspace(getch())) nextch();
if (isdigit(getch())) {
token = Number;
value = get_number();
} else {
switch(getch()){
case '+':
token = Add;
nextch();
break;
case '-':
token = Sub;
nextch();
break;
case '*':
token = Mul;
nextch();
break;
case '/':
token = Div;
nextch();
break;
case '(':
token = Lpar;
nextch();
break;
case ')':
token = Rpar;
nextch();
break;
case ';':
token = Semic;
nextch();
break;
case EOF:
token = Eof;
break;
default:
token = Others;
}
}
}
// 構文解析
Expr *expression(void);
Expr *term(void);
Expr *factor(void);
Expr *expression(void)
{
Expr *e = term();
while (true) {
switch (token) {
case Add:
get_token();
e = make_op2(Add2, e, term());
break;
case Sub:
get_token();
e = make_op2(Sub2, e, term());
break;
default:
return e;
}
}
}
Expr *term(void)
{
Expr *e = factor();
while (true) {
switch (token) {
case Mul:
get_token();
e = make_op2(Mul2, e, factor());
break;
case Div:
get_token();
e = make_op2(Div2, e, factor());
break;
default:
return e;
}
}
}
Expr *factor(void)
{
switch (token) {
case Lpar:
get_token();
Expr *e = expression();
if (token == Rpar)
get_token();
else
error("')' expected");
return e;
case Number:
get_token();
return make_number(value);
case Add:
get_token();
return make_op1(Add1, factor());
case Sub:
get_token();
return make_op1(Sub1, factor());
default:
error("unexpected token");
}
}
// 数式の評価
double eval(Expr *e)
{
switch (e->tag) {
case Num: return e->num;
case Add1: return eval(e->left);
case Sub1: return -eval(e->left);
case Add2: return eval(e->left) + eval(e->right);
case Sub2: return eval(e->left) - eval(e->right);
case Mul2: return eval(e->left) * eval(e->right);
case Div2: return eval(e->left) / eval(e->right);
default:
fprintf(stderr, "invalid operator %d\n", e->tag);
exit(1);
}
}
void toplevel(void)
{
Expr *e = expression();
if (token == Semic) {
printf("=> %.16g\nCalc> ", eval(e));
fflush(stdout);
} else {
error("invalid token");
}
}
int main(void)
{
printf("Calc> ");
fflush(stdout);
nextch();
while (true) {
if (!setjmp(err)) {
get_token();
if (token == Eof) break;
toplevel();
} else {
// 入力のクリア
while (getch() != '\n') nextch();
printf("Calc> ");
fflush(stdout);
}
}
printf("bye\n");
return 0;
}
初版 2015 年 4 月 11 日
改訂 2023 年 4 月 8 日